Lesson 9: Implementing Agent Memory - Building Persistent Context for Intelligent Agents
[A] Today’s Build
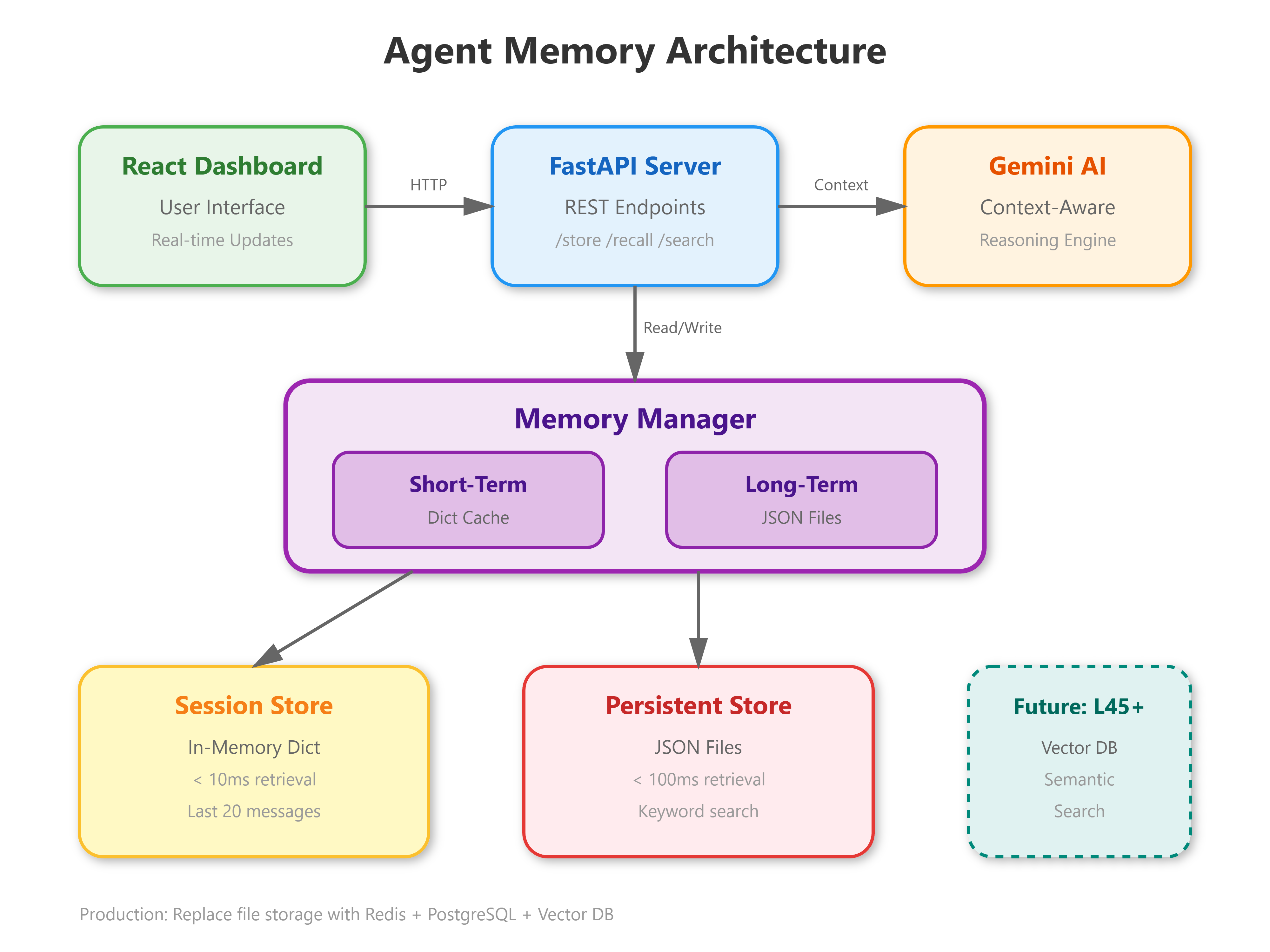
We’re building a dual-memory system that transforms stateless AI calls into agents that remember:
Short-term conversational memory using Python dictionaries for fast session context
Long-term persistent storage with file-based JSON for cross-session recall
Memory retrieval API that intelligently fetches relevant context
React dashboard showing real-time memory updates and retrieval patterns
Integration bridge connecting L8’s decision_maker to memory-aware reasoning
This lesson takes L8’s basic decision_maker function and equips it with memory—the critical difference between a one-shot API call and a true agent. We’re laying the foundation for L10’s SimpleAgent class, which will use these exact memory patterns to demonstrate goal-seeking behavior with retained context.
[B] Architecture Context
In our 90-lesson VAIA curriculum, L9 sits at the critical juncture where we transform reactive systems into proactive agents. Module 1 established LLM foundations (L1-L6), L7-L8 introduced agent theory, and now L9 implements the memory layer that makes autonomy possible.
L8 gave us decision_maker(context) that reasons about situations—but each call started from zero. L9 adds remember() and recall() capabilities, enabling the agent to build understanding over time. This persistent context becomes essential for L10’s goal-seeking behavior and every subsequent lesson through L90.
Module Integration: We’re completing the “Agent Fundamentals” block (L7-L10) by adding the memory component to L8’s planning and deliberation framework. This memory system will support tools integration (L11-L15), then scale through distributed patterns (L30-L40) and production deployment (L60-L90).
[C] Core Concepts
Conversational Memory vs. Long-Term Storage
Netflix’s recommendation agent doesn’t forget what you watched yesterday. Stripe’s fraud detection agent learns from historical patterns. The difference between useful and annoying AI lies in memory architecture.
Short-term memory handles active conversation—think of it as working RAM. A customer service agent needs to remember “The user mentioned their order #12345 three messages ago” without re-reading the entire transcript. We implement this with a simple Python dict keyed by session_id, storing message history and extracted facts.
Long-term memory persists across sessions—your hard drive equivalent. When that same customer returns next week, the agent should recall their previous issue, preferences, and resolution. We serialize this to JSON files, enabling retrieval by user_id, topic, or semantic similarity.
The Production Reality: At Netflix scale, you’re not using file storage—you’re using Redis clusters for short-term (microsecond retrieval) and vector databases like Pinecone for long-term semantic search. But the architecture patterns remain identical: fast working memory + persistent semantic storage + intelligent retrieval.