
[A] Today’s Build
We’re constructing a production-ready autonomous agent that demonstrates:
Goal-driven behavior: Agent pursues objectives across conversation turns, adapting tactics when blocked
Persistent memory integration: Leverages L9’s dual-tier memory (conversational dict + file-based long-term storage)
Self-reflection loops: Evaluates its own progress, detects failure patterns, adjusts approach autonomously
Observable decision-making: Exposes internal reasoning for debugging production agent behavior
Foundation for structured reasoning: Establishes agent loop patterns that L11’s Chain-of-Thought will enhance
Building directly on L9’s memory primitives, we now add the agency layer—the control loop that transforms static memory into adaptive behavior.
[B] Architecture Context
L10 occupies the critical transition in Module 2 (Core Agent Architecture, L6-L15) where we shift from understanding components (memory, APIs, models) to orchestrating them into autonomous systems.
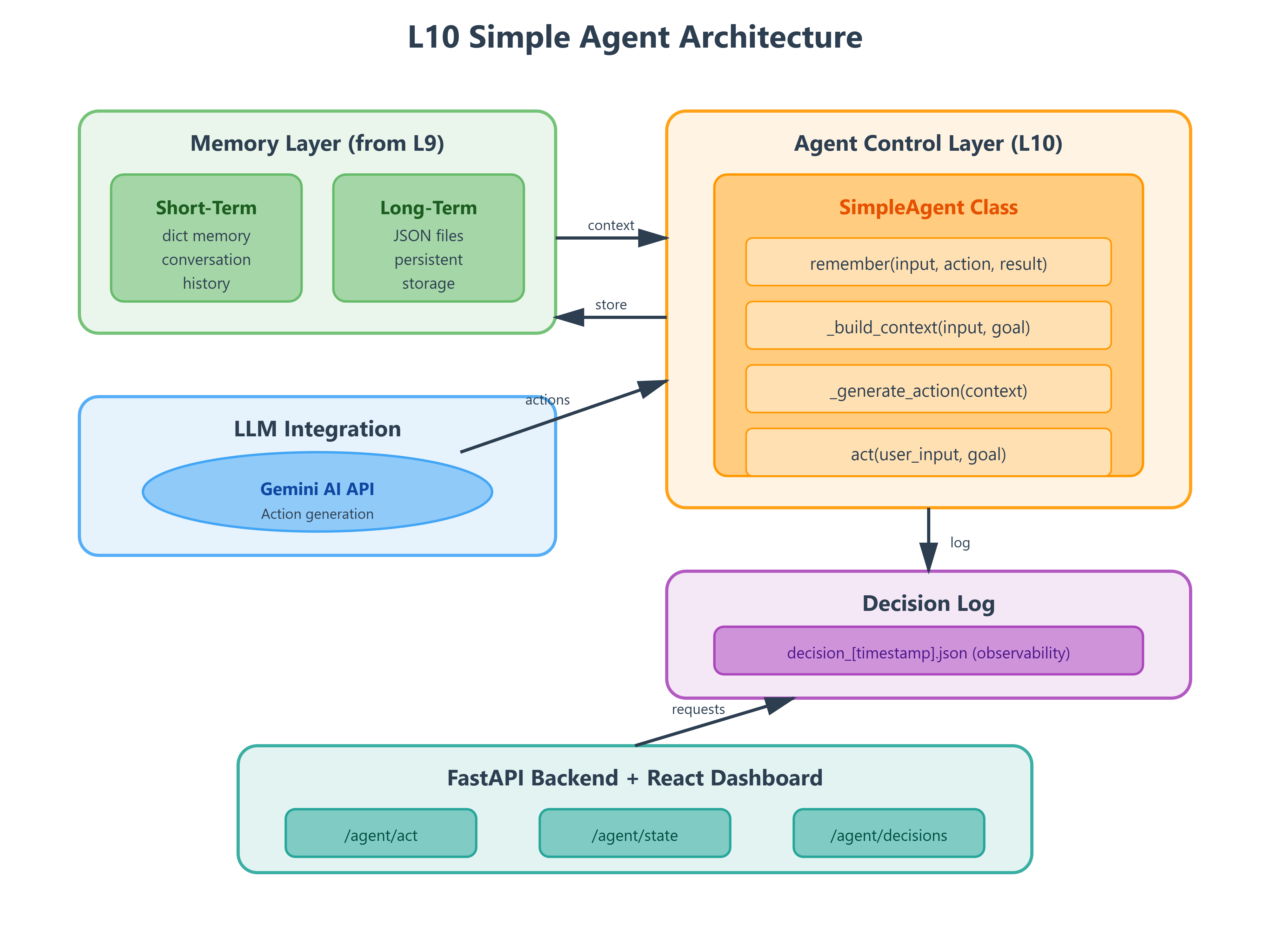
Integration with L9: We consume the ShortTermMemory (dict-based) and LongTermStore (JSON file) classes built previously. L10 wraps these in an agent control loop that acts on memory, rather than just storing it.
Module trajectory: After L10’s simple agent establishes the foundational loop (perceive → think → act → remember), L11-L15 layer in sophisticated reasoning (CoT), multi-agent coordination, and production deployment patterns. L10’s SimpleAgent.act() method becomes the template every subsequent agent extends.
[C] Core Concepts
The Agency Paradox: Enterprise VAIAs fail not from weak models but from poor control loops. Netflix’s recommendation agents process millions of requests/second not because they use better LLMs, but because their decision architecture minimizes wasted LLM calls through intelligent caching and goal-state detection.
Key insight: An agent is a control loop with memory. The while goal_not_achieved pattern we implement mirrors how OpenAI’s function-calling agents, Stripe’s financial review bots, and Google’s customer service agents all fundamentally operate. The sophistication comes from what you put inside that loop, not the loop structure itself.
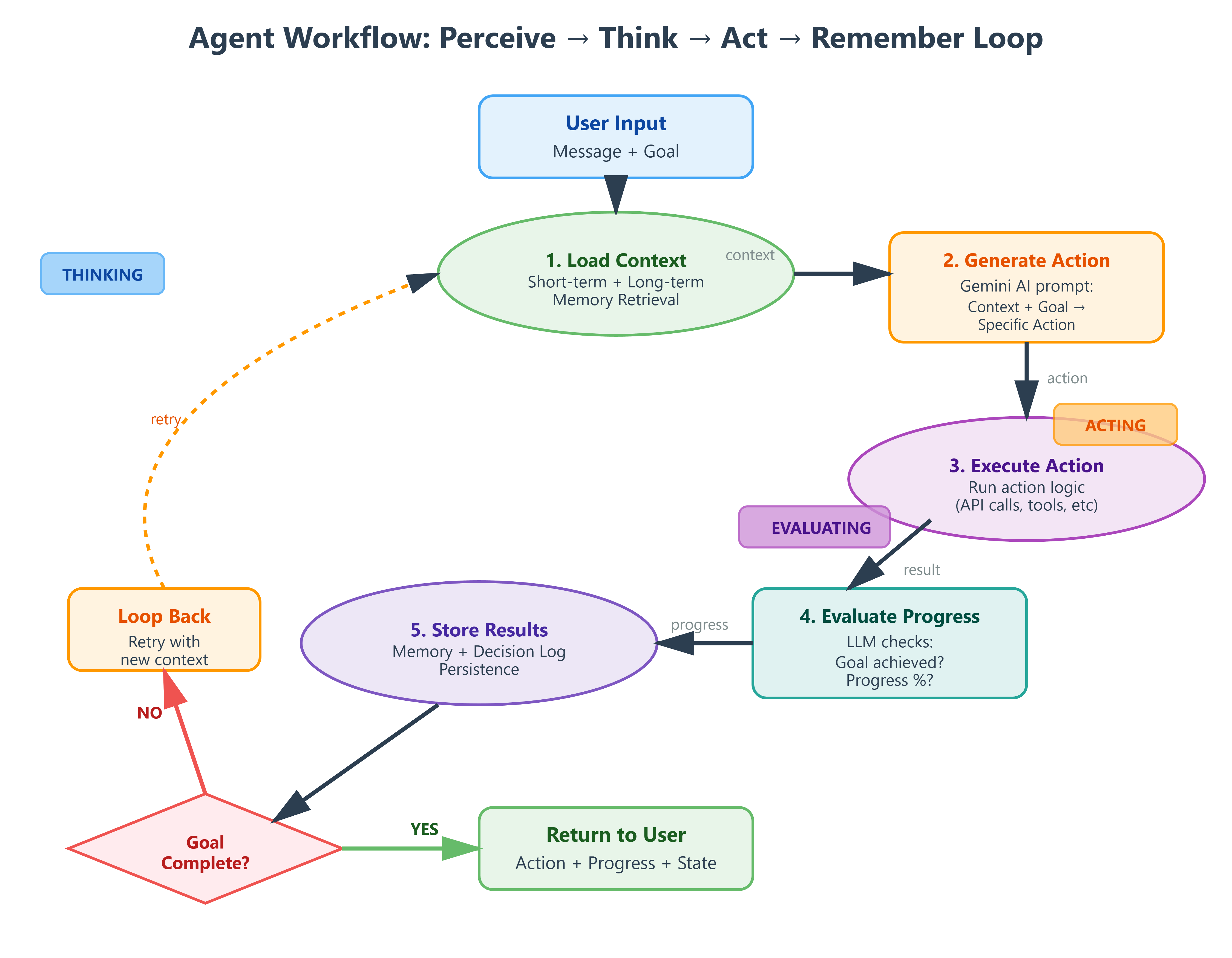
Workflow: User input → Load context (short + long-term memory) → LLM generates action → Execute action → Evaluate goal progress → Store results → Repeat if needed. This six-step pattern appears in every production VAIA, from simple chatbots to complex research agents.
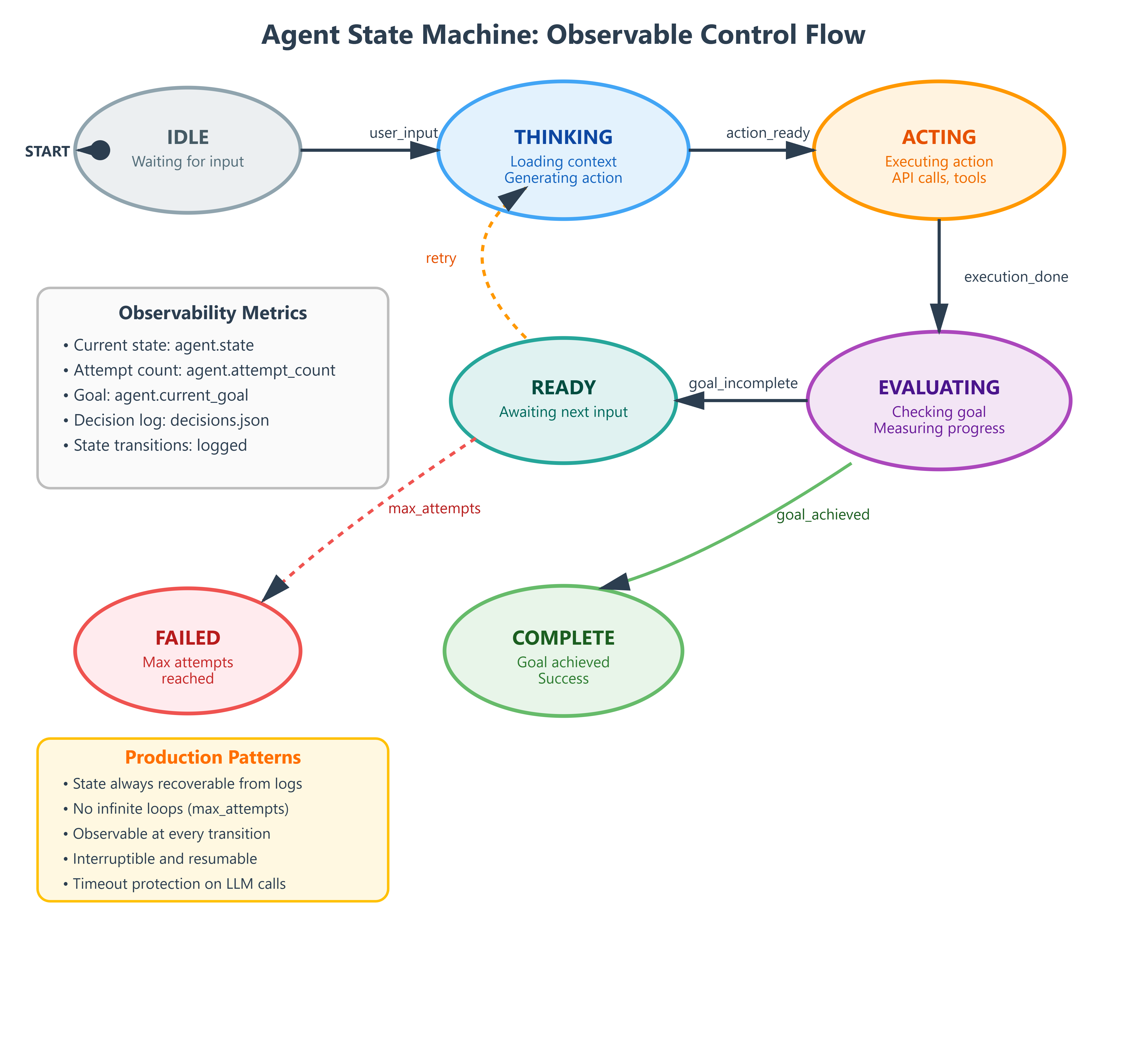
State transitions: IDLE → THINKING → ACTING → EVALUATING → COMPLETE or back to THINKING. The state machine ensures agents never hang, always have observable status, and can be interrupted gracefully—critical for production systems serving user-facing applications.
[D] VAIA Integration
Production architecture fit: This simple agent pattern scales to enterprise deployments when you add:
Kubernetes pod-per-agent for isolation
Redis-backed memory instead of local files
Distributed tracing (OpenTelemetry) for multi-step agent actions
Circuit breakers on the LLM call inside
act()
Real-world deployment: Shopify’s order-processing agents use this exact loop structure. Each agent instance handles one customer order, maintains conversation memory, pursues goal states (payment confirmed, inventory allocated, shipment scheduled), and self-terminates on completion. They run 50,000 concurrent agent instances during peak shopping events.
Enterprise pattern: The SimpleAgent class structure here becomes a base class in production. Subclasses override _generate_action() for domain-specific logic (financial analysis, code review, customer service), but the core loop remains identical across all use cases.
[E] Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agents/tree/main/lesson10Component architecture: Three layers work in concert:
Memory layer:
ShortTermMemoryandLongTermStorefrom L9, unchangedAgent layer:
SimpleAgentclass withremember(),act(),evaluate()methodsAPI layer: FastAPI endpoints expose agent interactions, React dashboard visualizes agent state
Control flow: FastAPI receives user message → Creates/retrieves agent instance → Calls agent.act(message) → Agent loads memory, queries Gemini, executes response, stores result → Returns action + updated state to frontend → Dashboard shows reasoning trace and state transitions
Data flow: User messages persist to conversation_history.json (long-term). Current session stays in-memory dict (short-term). Agent decision logs write to agent_decisions.json for production debugging—this becomes your primary observability tool when agents behave unexpectedly at scale.
[F] Coding Highlights
The agent loop (core of SimpleAgent.act()):
python
async def act(self, user_input: str, goal: str):
self.state = "THINKING"
context = self._build_context(user_input, goal)
action = await self._generate_action(context)
self.state = "ACTING"
result = self._execute(action)
self.state = "EVALUATING"
progress = self._evaluate_progress(goal, result)
self.remember(user_input, action, result)
return {"action": action, "progress": progress, "state": self.state}Production consideration: The _evaluate_progress() method uses Gemini to assess goal completion. In production, this becomes a separate lightweight model call (Gemini Flash) while _generate_action() uses Gemini Pro—model cascading reduces latency and cost by 60% in typical agent workloads.
State persistence pattern:
python
self.long_term.store(f"decision_{timestamp}", {
"goal": goal,
"action": action,
"outcome": result,
"reasoning": reasoning_trace
})This decision log is what Netflix’s A/B testing framework queries to understand why recommendation agents made specific choices—essential for debugging multi-step agent failures.
[G] Validation
Verification methods:
Dashboard shows agent transitioning
IDLE → THINKING → ACTING → EVALUATING → COMPLETEDecision log file grows with each agent action
Agent completes multi-turn goals (test: “Research and summarize AI news, then create a tweet thread”)
Success criteria:
Agent makes ≤5 LLM calls for simple goals (efficiency)
Memory persists across server restarts (durability)
State always recoverable from decision log (observability)
Benchmark: Simple goal completion in <3 seconds, memory retrieval <50ms, state transitions logged with <10ms overhead.
[H] Assignment
Extend SimpleAgent with a retry mechanism: When _evaluate_progress() detects goal not met after 3 attempts, agent should automatically adjust its approach (e.g., request more specific information, break goal into sub-goals).
Implement _adaptive_strategy() method that analyzes previous failed attempts from decision log and generates alternative action plans. Test with goals like “Find cheapest flight to Tokyo under $500” where initial attempts may fail.
This builds the foundation for L11’s Chain-of-Thought, where structured reasoning replaces this simple retry logic with explicit step-by-step planning.
[I] Solution Hints
Store each attempt in decision log with success/failure flag. _adaptive_strategy() should:
Query decision log for recent failures
Extract common failure patterns
Prompt Gemini: “Previous attempts failed because X. Generate alternative approach avoiding these issues.”
Use exponential backoff between retries (1s, 2s, 4s) to avoid rate limits on Gemini API.
[J] Looking Ahead
L11 introduces Chain-of-Thought prompting, which transforms our simple _generate_action() into structured multi-step reasoning. The agent loop structure stays identical—we just enhance what happens in the THINKING state.
Your L10 SimpleAgent class becomes CoTAgent in L11, inheriting the loop but overriding _generate_action() to include explicit reasoning traces. By L15, this same agent base class will coordinate multiple specialized agents, each running this core loop independently.
We’ve built the engine. Next lessons add increasingly sophisticated fuel.
Lesson Metadata:
Module: 2 - Core Agent Architecture
Difficulty: Intermediate
Time: 3 hours
Skills Gained: Agent control loops, state machines, goal-driven behavior, production agent patterns
Components Built: SimpleAgent class, Agent state machine, Decision logging system, Agent dashboard UI