Lesson 11: Prompt Engineering Mastery: Chain-of-Thought (CoT)
[A] Today’s Build
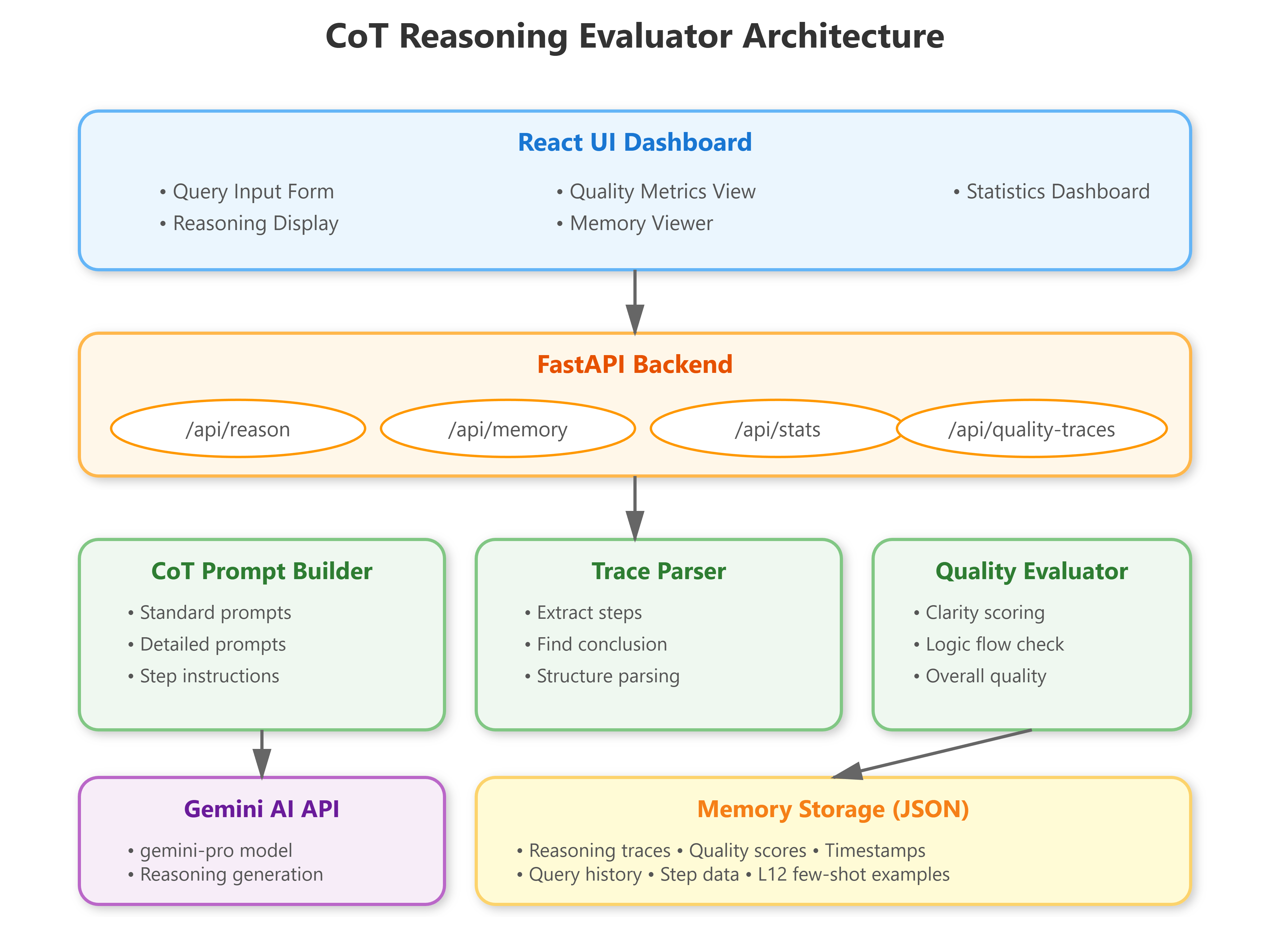
We’re building a CoT Reasoning Evaluator that:
Implements structured Chain-of-Thought prompting with explicit reasoning traces
Evaluates LLM reasoning quality with automated scoring metrics
Extends L10’s SimpleAgent with CoT-aware memory and reasoning capabilities
Provides a visual dashboard for analyzing reasoning step clarity and logical flow
This builds on L10’s SimpleAgent foundation by adding sophisticated reasoning analysis capabilities. The system prepares for L12’s few-shot prompting by establishing baseline reasoning quality metrics.
[B] Architecture Context
L11 sits in Module 2: Prompt Engineering & Agent Communication of the 90-lesson VAIA curriculum. We’re evolving from L10’s basic agent memory into structured reasoning patterns that enterprise VAIAs use for complex decision-making.
Integration points:
Extends L10’s
SimpleAgentclass withreason_with_cot()methodReuses memory persistence layer from L10
Establishes reasoning trace storage for L12’s few-shot example selection
Module objectives: Master prompt engineering techniques that control LLM behavior at scale—critical for production VAIAs handling diverse reasoning tasks.
[C] Core Concepts
Chain-of-Thought prompting forces LLMs to externalize reasoning steps before reaching conclusions. Instead of direct answers, the model articulates intermediate thinking: “First, I’ll identify... Then, I’ll calculate... Therefore...”
Why this matters for VAIAs: Production systems need auditable decisions. When a VAIA rejects a loan application or escalates a security alert, stakeholders demand transparent reasoning chains. CoT provides this audit trail.
Key workflow patterns:
Structured prompts - Explicit instructions: “Think step-by-step. Show your reasoning.”
Reasoning extraction - Parse LLM output into discrete reasoning steps
Quality evaluation - Score clarity, logical flow, step completeness
Trace persistence - Store reasoning chains for analysis and few-shot examples