[A] Today’s Build
What We’re Building:
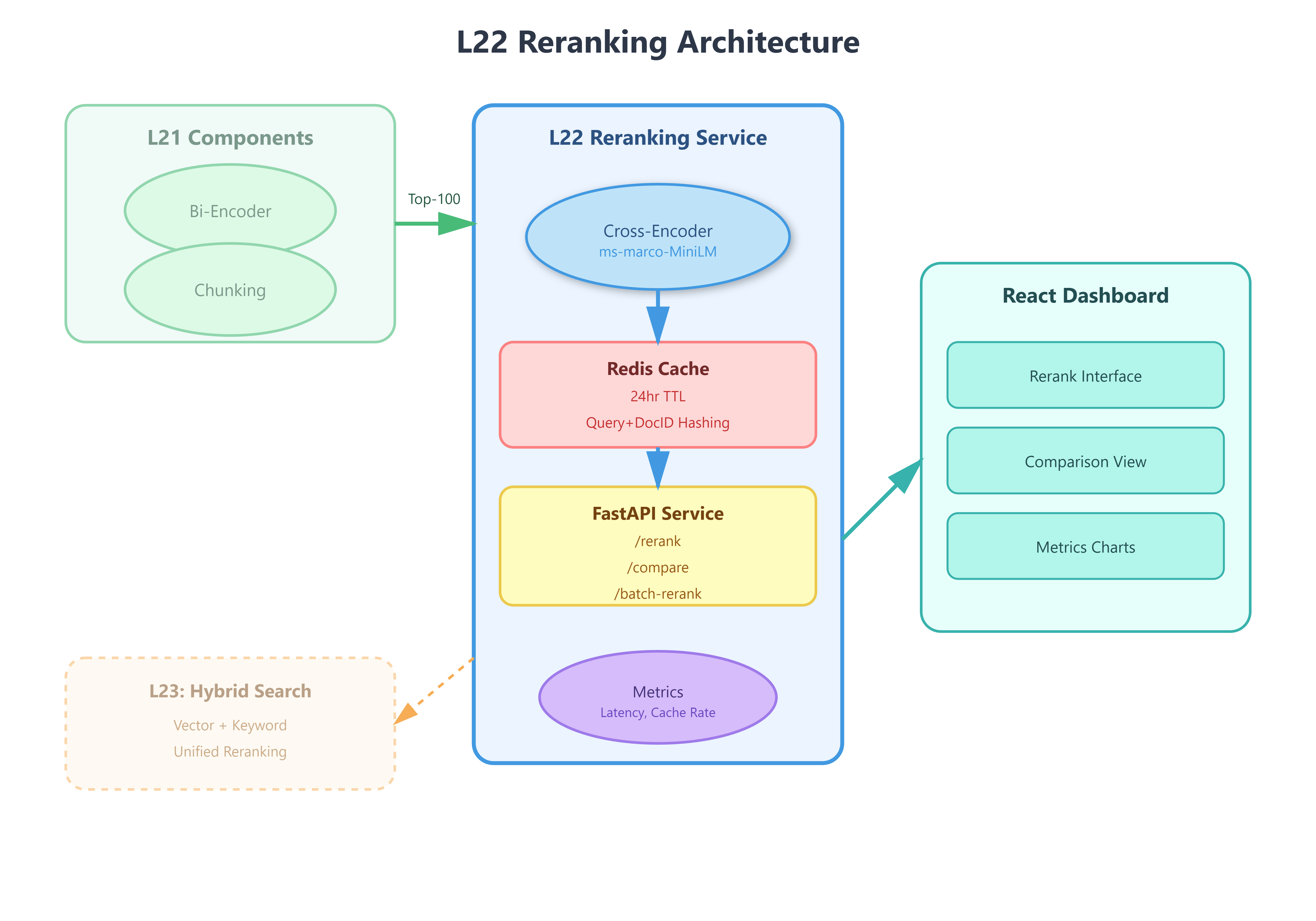
Cross-encoder reranking pipeline that rescores retrieved documents
Integration with L21’s embedding/chunking infrastructure
Real-time reranking dashboard showing relevance score improvements
Production-ready reranking service with caching and batch processing
Comparative metrics system demonstrating retrieval quality gains
Building on L21: We leverage the advanced chunking strategies and Sentence Transformer embeddings from the previous lesson, adding a critical post-retrieval layer that dramatically improves result quality.
Enabling L23: This reranking foundation is essential for hybrid search—you can’t effectively combine vector and keyword results without sophisticated reranking to unify disparate scoring systems.
[B] Architecture Context
Position in 90-Lesson Path: L22 sits in Module 4 (RAG Implementation), bridging initial retrieval (L20-21) with advanced search optimization (L23-25). This lesson introduces the critical insight that retrieval and ranking are separate concerns in production systems.
Integration with L21: We build directly on L21’s chunking pipeline and embedding service, adding a reranking layer that operates on the retrieved candidates. The semantic chunking output from L21 becomes reranking input.
Module Objectives: We’re building toward production RAG systems where retrieval quality directly impacts LLM answer accuracy. Reranking is the production pattern used by Perplexity, You.com, and enterprise search platforms to achieve 30-40% relevance improvements.
Component Architecture:
FastAPI reranking service with Hugging Face cross-encoder model
Redis cache for reranked results (24hr TTL)
React dashboard showing before/after relevance scores
Integration layer connecting to L21’s retrieval service
Metrics collector tracking reranking impact