
Lesson 25: Advanced Prompting for RAG - System Prompts That Prevent Hallucination
Nothing teaches better than “Code in Action”.
Start afresh with AI & ML Engineering Two Everyday coding Courses.
Learn AI Agents : Join the AI agent revolution before your competition does.
Explore more hands-on courses our portal
Lifetime Access : 4 hands on courses + full portal with Pro Max offer → link
[A] Today’s Build
We’re building a sophisticated prompt engineering framework that transforms raw retrieval into reliable answers:
Grounding-enforced system prompts that force LLMs to stay within retrieved context boundaries
Irrelevance detection layer that tests whether the LLM can reject off-topic contexts
Citation-tracking mechanism that maps every answer claim back to source chunks
Prompt template library with domain-specific patterns (legal, medical, financial)
Automated adversarial testing that intentionally injects misleading context
This builds directly on L24’s modular LangChain pipeline by replacing generic prompts with production-grade grounding strategies. We’re taking the RetrievalQA chain and teaching it to say “I don’t know” when context is insufficient—the hardest problem in RAG systems.
This enables L26’s multi-turn conversations by establishing the grounding discipline that prevents context drift across dialogue turns.
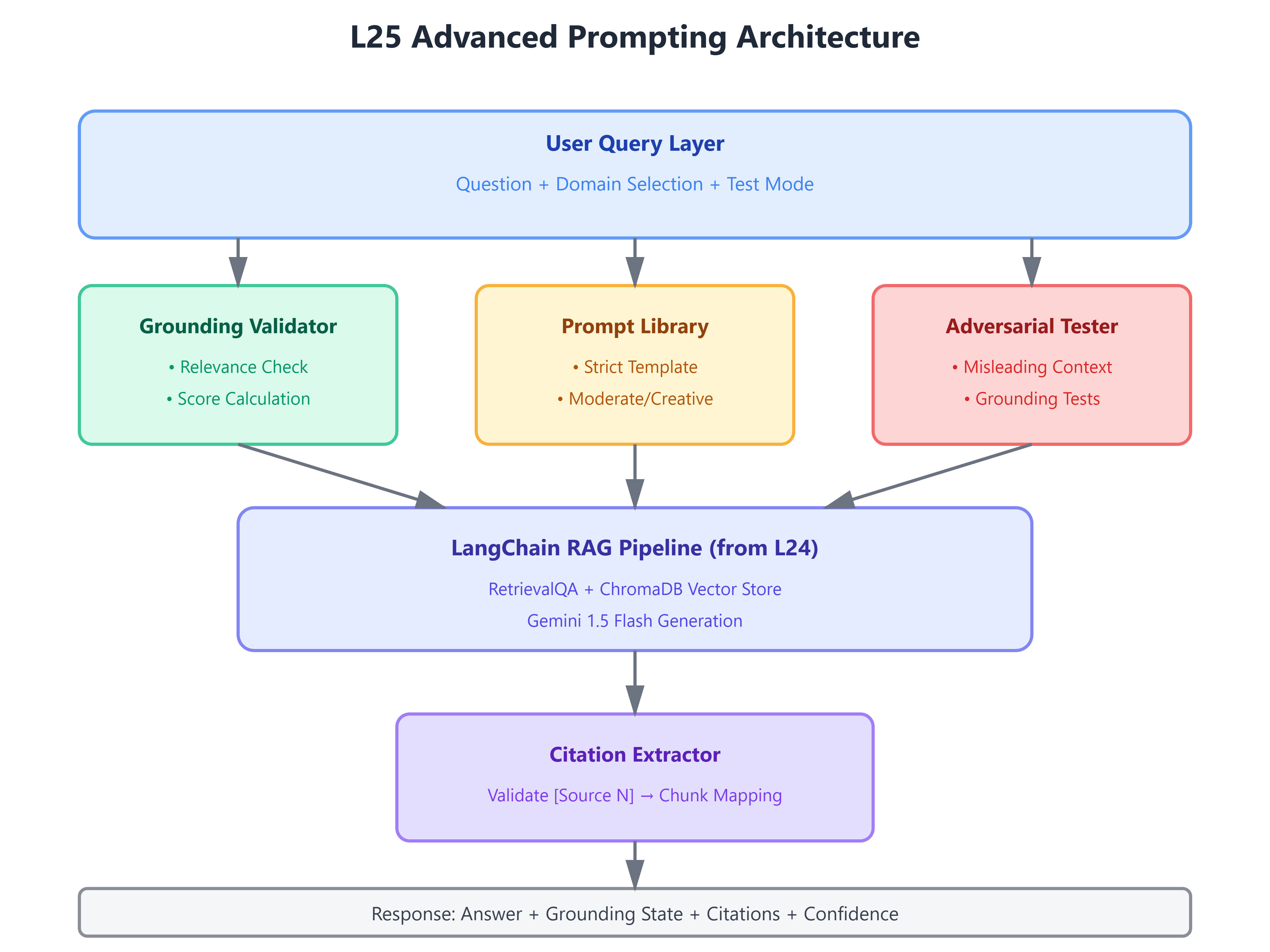
[B] Architecture Context
L25 sits at the critical intersection between retrieval mechanics (L20-L24) and conversation intelligence (L26-L30). While previous lessons optimized what we retrieve, this lesson optimizes how the LLM interprets retrieval results.
We integrate with L24’s LangChain components by:
Wrapping the existing RetrievalQA with custom prompt templates
Injecting grounding validators before generation
Adding citation extractors after generation
The module’s objective—building production RAG systems—requires this lesson because 80% of RAG failures in production stem from prompt design, not retrieval quality. Netflix’s recommendation explanations, Stripe’s documentation assistant, and Notion’s Q&A all use variants of these patterns.
[C] Core Concepts
Grounding vs. Hallucination: Standard LLMs generate plausible-sounding answers from their training data. RAG systems must override this behavior by conditioning generation strictly on retrieved chunks. The challenge: LLMs naturally blend parametric knowledge with provided context unless explicitly instructed otherwise.
The Irrelevance Test: Production RAG must handle queries where retrieval returns nothing useful. A properly grounded system responds “The provided documents don’t contain information about X” rather than fabricating answers. This requires teaching the LLM to evaluate context relevance before answering.
Citation Architecture: Enterprise RAG systems (legal, medical, financial) require traceability. Every generated claim must reference specific source chunks. This workflow operates in three stages:
Retrieval returns chunks with IDs
System prompt demands inline citations: “[Source 1]”, “[Source 2]”
Post-processing validator checks all citations exist in retrieval results
Prompt Hierarchies: Different domains require different grounding strengths:
Legal/Medical: “NEVER generate information not explicitly stated in context. If uncertain, respond ‘Insufficient information.’”
Customer Support: “Prioritize context, but acknowledge related concepts from training if helpful.”
Creative Briefs: “Use context as inspiration; expand with relevant knowledge.”
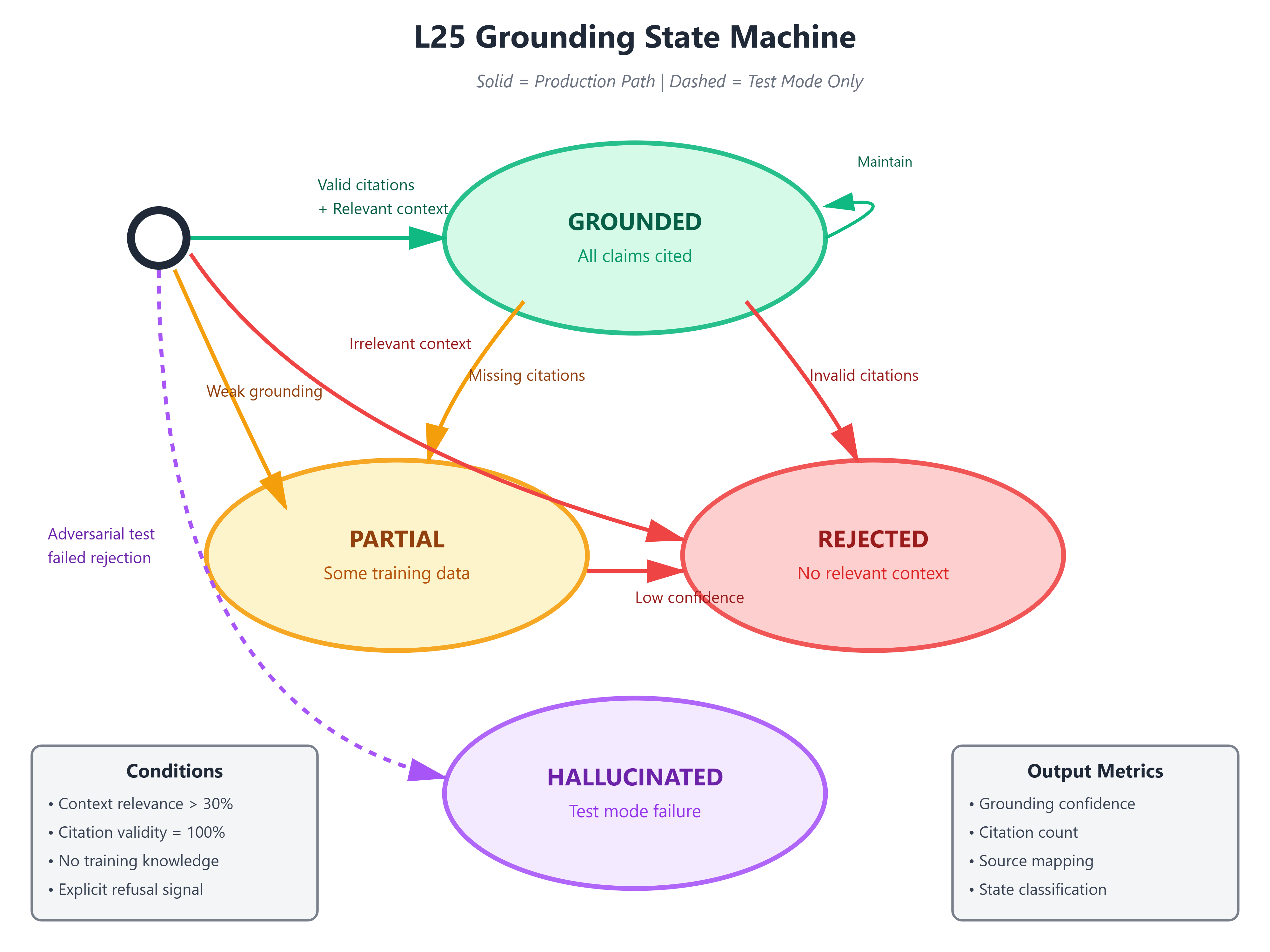
State Machine: The prompt engineering system manages three states:
Grounded: Answer fully supported by context with citations
Partial: Some claims grounded, some from training (flagged)
Rejected: No relevant context; explicit refusal to answer
[D] VAIA Integration
This lesson implements the grounding layer present in every production VAIA:
Intercom’s Resolution Bot: Uses strict grounding prompts that prevent the AI from inventing troubleshooting steps not documented in their knowledge base. Their system prompt includes: “Only reference solutions documented in the provided articles. If no article covers this issue, escalate to human support.”
Shopify’s Merchant Assistant: Employs domain-specific prompt templates that distinguish between policy information (strict grounding) and general advice (training knowledge allowed). Different prompt strategies for compliance vs. guidance.
OpenAI’s ChatGPT Enterprise: The “Search Bing and answer” pattern uses grounding prompts that force citation of search results. The system prompt explicitly prohibits stating “According to Bing...” without actual search result evidence.
Architecture Pattern: Production VAIAs implement a three-layer prompt stack:
System Layer: Domain rules, grounding constraints, output format
Context Layer: Retrieved chunks with metadata (source, timestamp, relevance score)
User Layer: The actual question with conversation history
[E] Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agents/tree/main/lesson25/l25-advanced-prompting-ragOur system architecture separates prompt engineering from retrieval mechanics:
Component Architecture:
PromptTemplateLibrary: Domain-specific system prompts (legal, support, creative)GroundingValidator: Pre-generation checker that evaluates context relevanceCitationExtractor: Post-generation parser that verifies claim-to-source mappingAdversarialTester: Injects misleading context to measure grounding strengthPromptOptimizer: A/B tests different prompt formulations with ground truth data
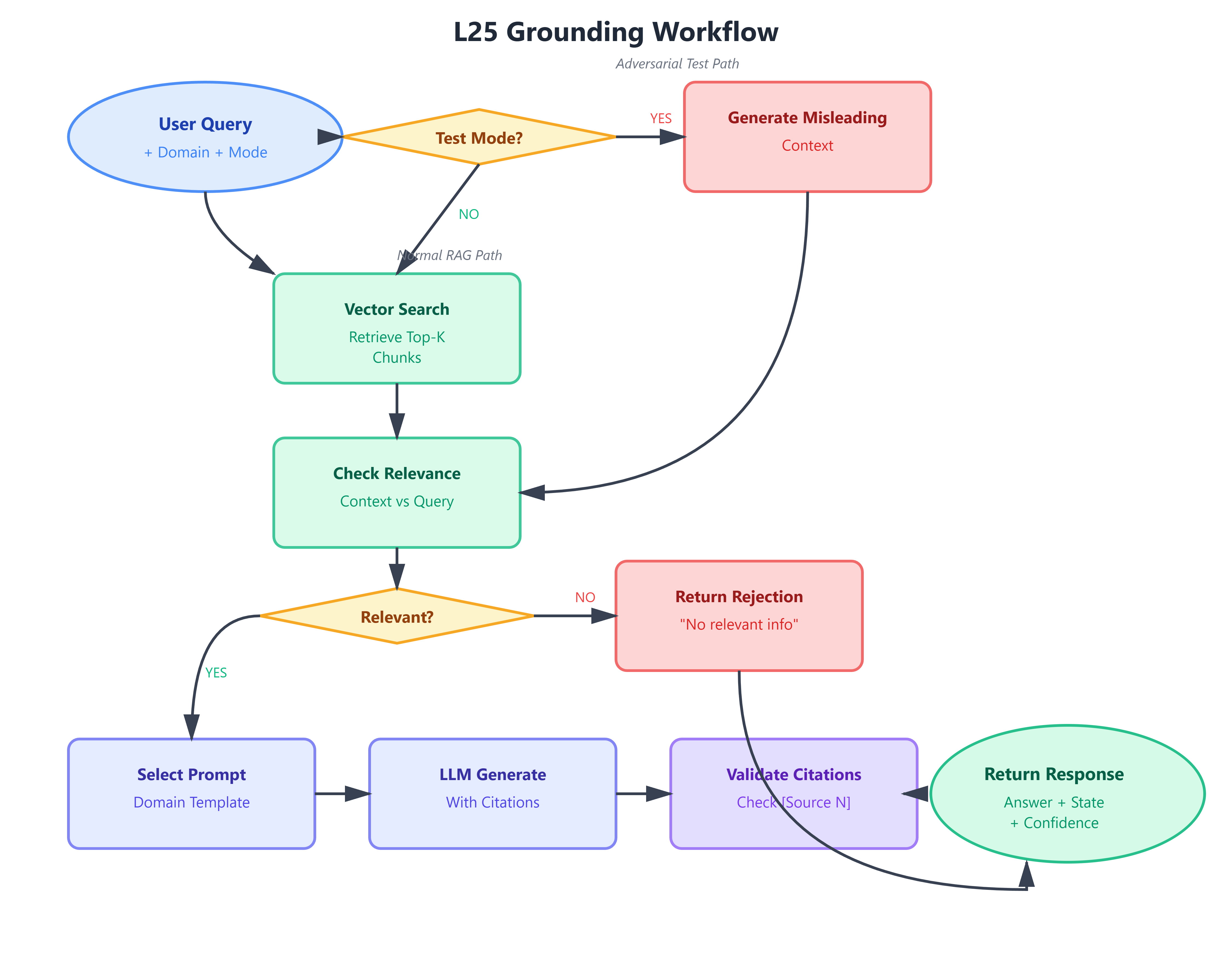
Control Flow:
User query triggers retrieval (from L24’s vector store)
GroundingValidator examines chunks for relevance
If irrelevant, return early with “No relevant context” response
If relevant, PromptTemplateLibrary selects domain-appropriate template
LangChain RetrievalQA generates answer with citations
CitationExtractor validates all references exist in chunks
Response marked as Grounded/Partial/Rejected
Data Flow:
Retrieved chunks carry metadata:
{id, text, score, source}System prompt template receives:
{chunks, domain, strictness_level}Generated response structure:
{answer, citations, grounding_confidence, sources_used}
[F] Coding Highlights
Grounding-Enforced System Prompt:
python
STRICT_GROUNDING_TEMPLATE = """You are a precise information assistant.
CONTEXT:
{context}
RULES:
1. Answer ONLY using information explicitly stated in CONTEXT
2. Include citations: [Source 1], [Source 2], etc.
3. If CONTEXT doesn't contain the answer, respond: "The provided documents do not contain information about [topic]."
4. NEVER use your training knowledge to supplement CONTEXT
Question: {question}
Answer with citations:"""Irrelevance Detection:
python
def test_grounding(prompt_template, llm):
"""Test with intentionally irrelevant context"""
irrelevant_context = "The history of Japanese pottery spans 10,000 years..."
question = "What is the capital of France?"
response = llm.invoke(prompt_template.format(
context=irrelevant_context,
question=question
))
# Proper grounding should refuse to answer
assert "do not contain" in response.lower() or "insufficient" in response.lower()Citation Validation:
python
def validate_citations(answer, retrieved_chunks):
"""Ensure all cited sources exist"""
cited_ids = re.findall(r'\[Source (\d+)\]', answer)
available_ids = {chunk.metadata['id'] for chunk in retrieved_chunks}
invalid = set(cited_ids) - available_ids
if invalid:
raise CitationError(f"Answer cites non-existent sources: {invalid}")Production Consideration: Cache prompt templates per domain rather than generating on each request. Netflix’s system uses pre-compiled prompt variants that load at startup, reducing latency from ~200ms to ~5ms.
[G] Validation
Grounding Strength Test:
Create adversarial dataset: questions paired with irrelevant contexts
Measure refusal rate (should be >95% for strict grounding)
Check for leaked training knowledge in responses
Citation Accuracy:
Generate 100 answers with retrieved context
Parse all citations:
[Source N]Verify every N maps to actual chunk ID
Target: 100% citation validity
Domain Benchmarks:
Legal RAG: Zero unsupported claims (verified by domain expert)
Support RAG: <2% hallucination rate (measured against ground truth)
Creative RAG: Grounding rate >60% (allows some creative expansion)
Success Criteria:
Dashboard shows grounding confidence per answer
Adversarial tests pass with >95% refusal rate
Citation validator runs without errors on production traffic
Prompt A/B tests converge within 500 queries
[H] Assignment
Extend the adversarial testing framework:
Build a PromptRobustnessTest class that:
Generates 50 question-context pairs where context is intentionally misleading (talks about similar but wrong topics)
Tests multiple prompt formulations against this adversarial set
Measures grounding strength: % of responses that correctly refuse to answer
Identifies which prompt variants are most resistant to hallucination
Prepare for L26: Add conversation history to the prompt template:
python
CONVERSATION_GROUNDING_TEMPLATE = """
CONVERSATION HISTORY:
{history}
CURRENT CONTEXT:
{context}
When answering, ground claims in CURRENT CONTEXT, but acknowledge what was discussed in CONVERSATION HISTORY.
"""Test how grounding behaves when previous turns discussed topics not in current context.
[I] Solution Hints
Adversarial Context Generation:
If question is about “Python async”, provide context about “JavaScript promises”
If question is about “2024 revenue”, provide context about “2022 revenue”
Topic similarity tests grounding better than random contexts
Measuring Grounding Strength:
Parse response for absolute statements without citations
Check for dates/numbers not present in context
Look for phrases like “typically”, “generally”, “usually” that indicate training knowledge
Prompt Optimization:
Start with strictest grounding, then relax constraints
Test with domain experts who know ground truth
A/B test requires >200 queries per variant for statistical significance
Multi-Turn Preparation:
Store previous contexts in conversation buffer
Distinguish “context from current turn” vs. “context from conversation history”
Teach LLM when to reference history vs. when to ignore it
[J] Looking Ahead
L26 introduces the complexity of multi-turn conversations where context evolves across dialogue. The grounding discipline we’ve established here becomes critical when handling:
Follow-up questions that reference previous context: “What about the pricing?” requires understanding what “the” refers to from earlier turns.
Context drift across turns: User might shift topics; grounding prevents the LLM from confusing contexts from different turns.
Ambiguity resolution using conversation history: “Is it still valid?” requires combining current retrieval with historical context to determine what “it” refers to.
L26’s ConversationBufferMemory will integrate with our grounding templates, creating a system that maintains strict source attribution even as conversation state evolves. The citation mechanism extends to cite both “Current Context: [Source 3]” and “From earlier in conversation: [Turn 2]”.
We’re building the discipline that makes conversational RAG reliable at scale—the same patterns that power ChatGPT’s enterprise deployments and Perplexity’s cited answers.
Youtube Demo Link:
Next: L26 - Handling Ambiguity & Multi-Turn RAG