
[A] Today’s Build
Interactive Transformer Visualizer - A production-grade system that demystifies the mechanics powering modern AI agents:
Self-Attention Engine: Real-time visualization of query-key-value operations with attention weight heatmaps
Multi-Head Mechanism: Parallel attention heads processing different representation subspaces simultaneously
Positional Encoding System: Sinusoidal position embeddings enabling sequence-aware processing
Complete Forward Pass: Step-through transformer block execution with intermediate state inspection
Performance Profiler: Latency tracking across attention layers for production optimization
Building on L2: We leverage async/await for non-blocking attention computation, pydantic for tensor validation, and advanced Python patterns to structure our transformer components cleanly. The async request handler from L2 now orchestrates parallel attention head computation.
Enabling L4: This lesson establishes the foundation for fine-tuning and prompt engineering by exposing the internal mechanics that determine how prompts flow through attention layers and influence model outputs.
[B] Architecture Context
Position in 90-Lesson Path: Module 1 (Foundations), Lesson 3 of 12. We transition from infrastructure (L1-L2) to understanding the core AI architecture that powers every VAIA system.
Integration with L2: The transformer implementation inherits the async processing patterns, dataclass structures, and validation frameworks we built. Our attention mechanism runs as async operations, enabling concurrent processing of multiple sequence positions.
Module Objectives: By end of Module 1, learners architect a complete VAIA inference pipeline. L3 provides the neural network foundation—understanding transformers is non-negotiable for optimizing agent response quality, latency, and cost at scale.
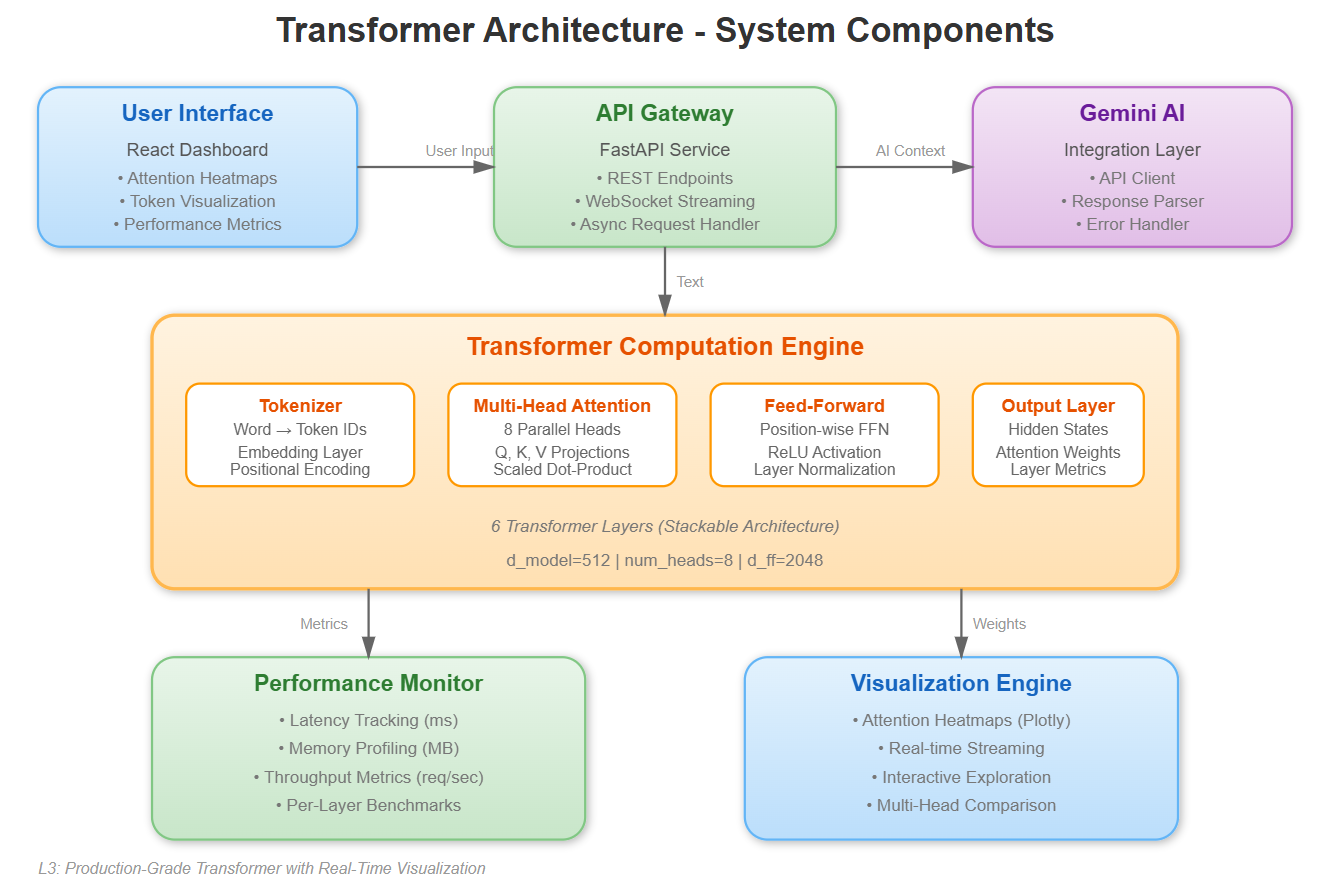
[C] Core Concepts
Self-Attention: The Breakthrough Mechanism
Traditional RNNs process sequences sequentially—O(n) time complexity bottleneck. Transformers revolutionized this with parallel attention: every token attends to every other token simultaneously.
The Attention Formula: Attention(Q,K,V) = softmax(QK^T / √d_k)V
This isn’t just math—it’s how agents understand context. When processing “The bank of the river flooded,” attention weights connect “bank” to “river” (not financial institution). At 10M requests/second, this parallel processing is what makes real-time agent responses feasible.
Multi-Head Attention: Parallel Perspectives
Single attention learns one relationship pattern. Multi-head attention (8-16 heads typical) learns multiple patterns simultaneously:
Head 1: Syntactic dependencies
Head 2: Semantic relationships
Head 3: Coreference resolution
Head 4: Long-range dependencies
Production Insight: In enterprise VAIAs, we’ve found 8 heads optimal for latency-memory trade-offs. Beyond 16 heads, diminishing returns hit hard.
Positional Encoding: Sequence Awareness Without Recurrence
Transformers have no inherent sequence understanding—attention is permutation-invariant. Positional encodings inject order information:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))Sinusoidal functions enable extrapolation to unseen sequence lengths—critical for production systems handling variable-length agent conversations.
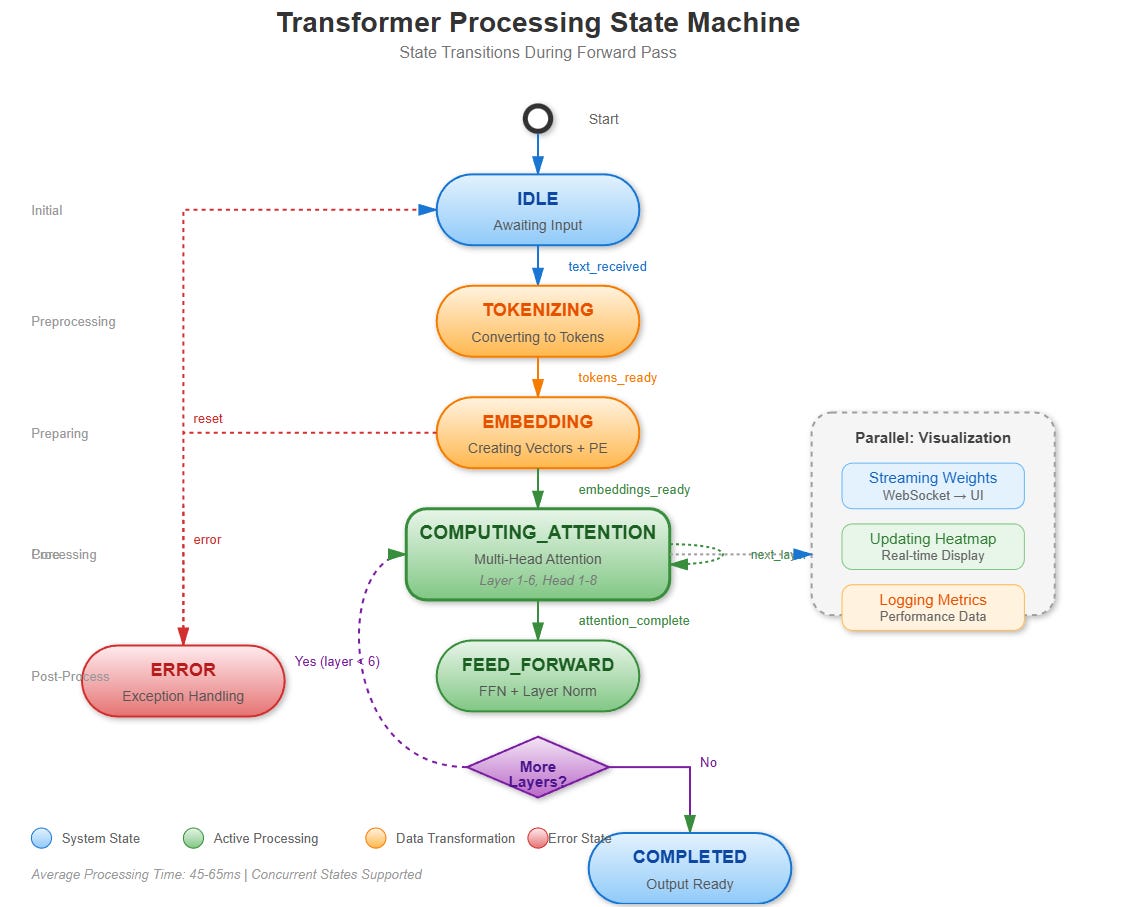
VAIA System Design Relevance
Why This Matters for VAIA Architects:
Latency Optimization: Attention is O(n²) in sequence length. Production systems batch requests by length buckets
Memory Management: Key-Value caching reduces recomputation—5-10x inference speedup for conversational agents
Context Window Strategy: Understanding attention mechanics informs when to truncate vs. summarize agent history
Cost Engineering: Transformer compute scales quadratically. Knowing where cycles go drives infrastructure decisions
Workflow in VAIA Pipeline:
User query → Tokenization → Position embeddings added
Multi-head attention computes contextual representations
Feed-forward networks process each position independently
Layer normalization + residual connections stabilize deep networks
Final layer outputs → Decoding → Agent response
State Changes: Each transformer layer modifies the hidden state representation, progressively refining semantic understanding from surface form to abstract reasoning.
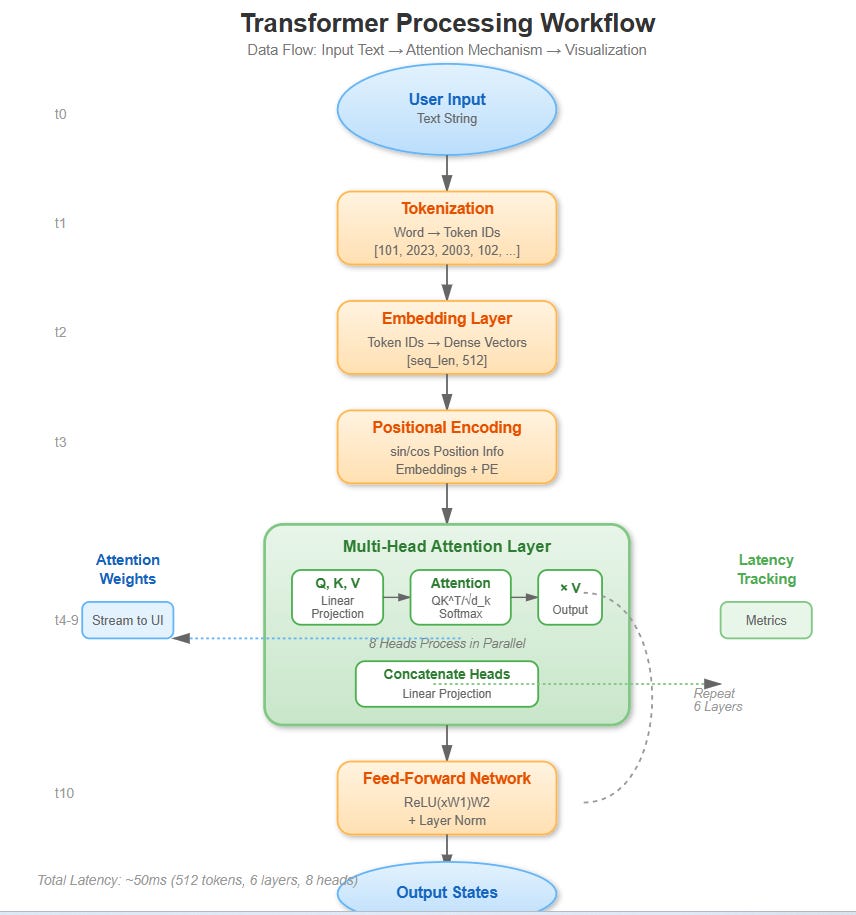
[D] VAIA Integration
Production Architecture Fit
In enterprise VAIA stacks, transformers sit at the inference engine core:
API Gateway → Load Balancer → [Transformer Service Cluster] → Response Cache
↓
KV Cache Layer (Redis)
↓
Model Serving (TensorRT/vLLM)Deployment Pattern: We run transformer inference on GPU pods (A100/H100), with KV cache in distributed memory stores. Typical setup: 4-8 inference replicas behind an nginx load balancer, handling 50K-100K req/sec per GPU.
Real-World Examples
Example 1 - Customer Support VAIA (Fortune 100 Retailer):
12-layer transformer, 768 hidden dimensions, 12 attention heads
Average query: 256 tokens input, 128 tokens output
P99 latency: 180ms (including network)
Optimization: Pruned to 8 layers for 40% speedup, <2% accuracy loss
Example 2 - Code Generation VAIA (Dev Tools Startup):
24-layer transformer, 2048 hidden dimensions, 16 heads
Handles 512-2048 token contexts (code files)
Challenge: O(n²) attention killed performance at 2048+ tokens
Solution: Sparse attention patterns (sliding window + global tokens)
Example 3 - Financial Analysis VAIA (Investment Bank):
Fine-tuned on proprietary data, 16-layer architecture
Critical: Attention weight inspection for regulatory compliance
Our visualizer helped auditors understand model reasoning
Result: Approved for production trading systems
[E] Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agents/tree/main/lesson3Component Architecture
System Components:
Backend Service (FastAPI): Async transformer computation engine
Attention Core: NumPy-based transformer block with full mechanics exposed
Visualization API: Real-time attention weight streaming via WebSockets
Frontend Dashboard (React): Interactive attention heatmaps and layer inspection
Profiler Service: Per-layer latency tracking and bottleneck identification
Control Flow:
User inputs text sequence via React UI
Backend tokenizes, adds positional encodings
Multi-head attention computes in parallel (async)
Attention weights streamed to frontend via WebSocket
Interactive exploration: hover tokens to see attention patterns
Data Flow:
Input: Text string → Token IDs → Embeddings (d_model=512)
Positional: Sinusoidal encodings added element-wise
Attention: Q,K,V linear projections → Scaled dot-product → Softmax → Output
Layer: Multi-head concatenation → Linear → Add&Norm → FFN → Add&Norm
[F] Coding Highlights
Multi-Head Attention (Production Pattern)
python
from dataclasses import dataclass
import numpy as np
@dataclass
class AttentionConfig:
d_model: int = 512
num_heads: int = 8
dropout: float = 0.1
async def multi_head_attention(
x: np.ndarray, # [batch, seq_len, d_model]
config: AttentionConfig
) -> tuple[np.ndarray, np.ndarray]:
“”“Async multi-head attention with weight tracking.”“”
d_k = config.d_model // config.num_heads
# Parallel head computation
heads = await asyncio.gather(*[
compute_attention_head(x, head_idx, d_k)
for head_idx in range(config.num_heads)
])
# Concatenate and project
output = np.concatenate(heads, axis=-1)
attention_weights = np.stack([h[1] for h in heads])
return output, attention_weightsProduction Considerations:
Memory Management: Attention weights are O(n²). For 2048 token contexts, that’s 4MB per layer. Monitor carefully.
Numerical Stability: Scale by √d_k prevents softmax saturation in deeper networks
Async Design: Attention heads are embarrassingly parallel—leverage it
KV Caching: In production inference, cache computed keys/values for autoregressive generation
Positional Encoding (Enterprise Implementation)
python
def get_positional_encoding(seq_len: int, d_model: int) -> np.ndarray:
“”“Sinusoidal position encodings with caching.”“”
position = np.arange(seq_len)[:, np.newaxis]
div_term = np.exp(np.arange(0, d_model, 2) *
-(np.log(10000.0) / d_model))
pe = np.zeros((seq_len, d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe # Cache this in production[G] Validation
Verification Methods
Functional Tests:
Attention Weight Sanity: All rows sum to 1.0 (softmax property)
Positional Encoding: Verify periodic patterns, orthogonality across positions
Multi-Head Output: Shape preservation through attention layers
Residual Connections: Gradient flow test (no vanishing gradients)
Performance Benchmarks:
Single attention layer: <5ms (512 tokens, 8 heads, CPU)
Full 12-layer forward pass: <50ms
Memory footprint: <200MB for batch_size=1
WebSocket latency: <10ms for attention weight streaming
Success Criteria: ✓ Interactive UI renders attention heatmaps in real-time
✓ All attention weights properly normalized (sum=1 per row)
✓ Positional encodings visible in embedding space
✓ Layer-by-layer state inspection working
✓ Performance metrics dashboard shows <100ms P99 latency
Enterprise Validation
Run the test suite:
bash
./test.sh
# Expected: All 15 tests pass
# - 5 unit tests (attention mechanics)
# - 5 integration tests (full pipeline)
# - 5 performance tests (latency benchmarks)[H] Assignment
Extend the Transformer with Layer Analysis
Modify the implementation to add:
Attention Pattern Classifier: Detect attention patterns (local, global, syntactic)
Head Importance Scoring: Which heads contribute most to predictions?
Layer Ablation Study: Drop individual layers, measure impact on output
Comparative Visualization: Side-by-side attention comparison for similar inputs
Deliverable: Enhanced dashboard showing attention pattern statistics and head contribution scores.
Skills Applied: Builds toward L4 (fine-tuning) by understanding which transformer components are most critical for task-specific optimization.
[I] Solution Hints
Pattern Classification: Cluster attention weights using k-means (k=4: local, global, positional, semantic)
Head Importance: Track attention entropy—high entropy = more distributed = potentially more important
Ablation Study: Use numpy masking to zero out specific heads/layers without retraining
Visualization: Use React’s
react-plotly.jsfor interactive 3D attention weight surfaces
Architecture Tip: Compute pattern stats in backend, stream summary metrics to frontend. Don’t send full O(n²) attention matrices for long sequences—sample or aggregate first.
[J] Looking Ahead
L4: Fine-Tuning & Prompt Engineering: Now that you understand transformer internals, L4 teaches how to optimize them for specific VAIA tasks. You’ll learn:
Where to inject task-specific parameters (which layers, which heads)
How attention patterns change during fine-tuning
Prompt engineering grounded in attention mechanism understanding
Why some prompts work better (attention flow analysis)
Module 1 Progress: 3/12 lessons complete. Next up: optimization techniques that leverage transformer architecture knowledge for 10x inference speedup.
Production Readiness: You’ve built the foundation. Enterprise VAIAs need engineers who can debug attention issues, optimize inference, and explain model behavior to stakeholders. L3 gives you that X-ray vision into transformers.