Introduction
What We Build
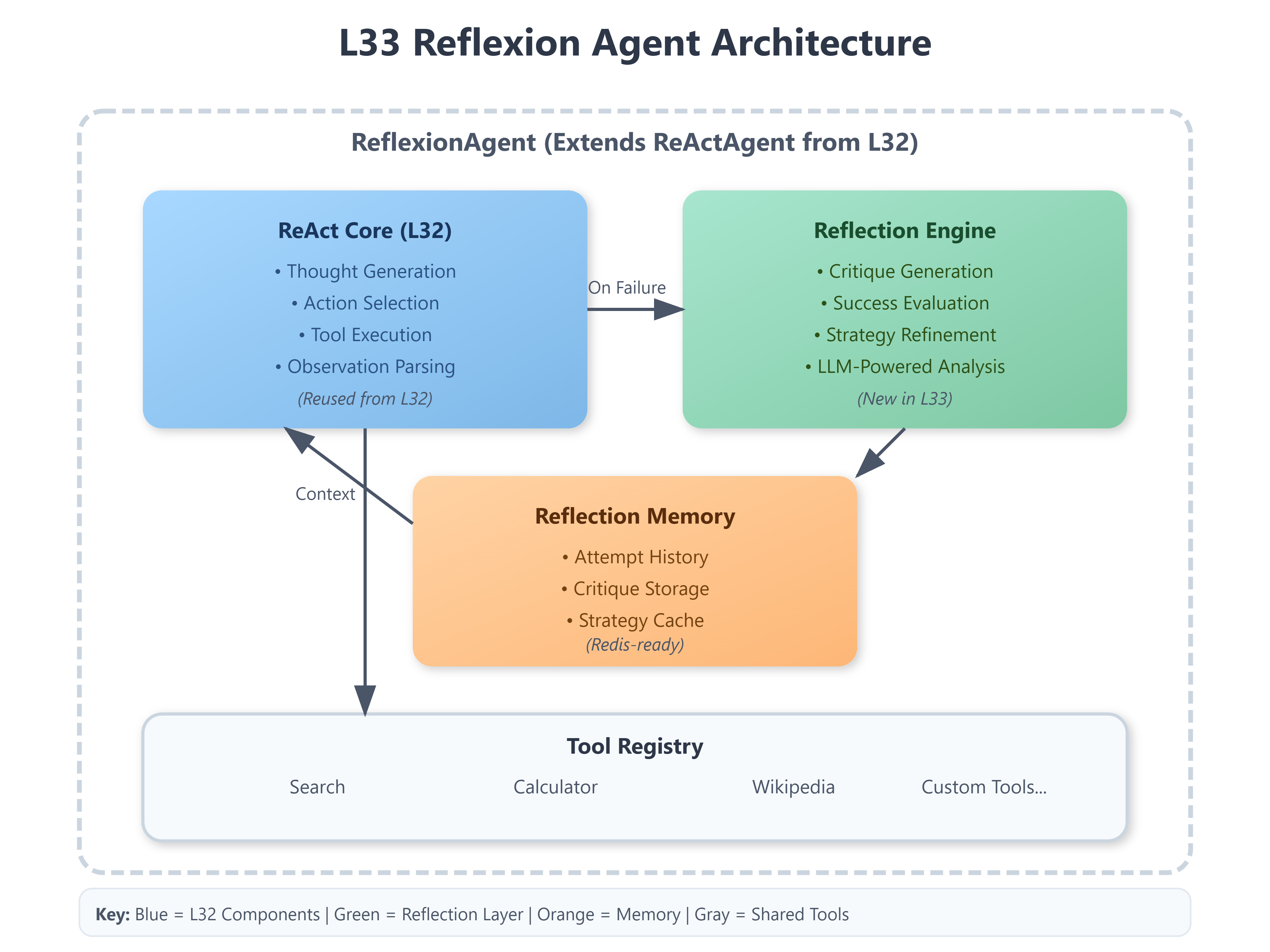
Reflexion loop integrated into ReAct agent from L32
Self-critique mechanism with LLM-powered evaluation
Memory system tracking reflections across iterations
Automatic plan refinement based on feedback
Production-grade error recovery patterns
Connection to Previous Lesson L32 established our foundational ReActAgent with tool execution. We now enhance it with self-awareness—the agent critiques its own reasoning, identifies failures, and iteratively improves outcomes without human intervention.
Enables Next Lesson L34 builds on our reflexion infrastructure by adding hard constraints (max_iterations, token budgets). The reflection memory we implement here becomes critical for understanding why agents hit limits and how to optimize within budgets.
Component Architecture
Core Components:
ReflexionAgent (extends ReActAgent from L32)
ReflectionEngine (LLM-powered critique generator)
ReflectionMemory (in-memory store, Redis-ready)
CriticPrompt (structured prompt for evaluation)