
A. Highlights
What We Build
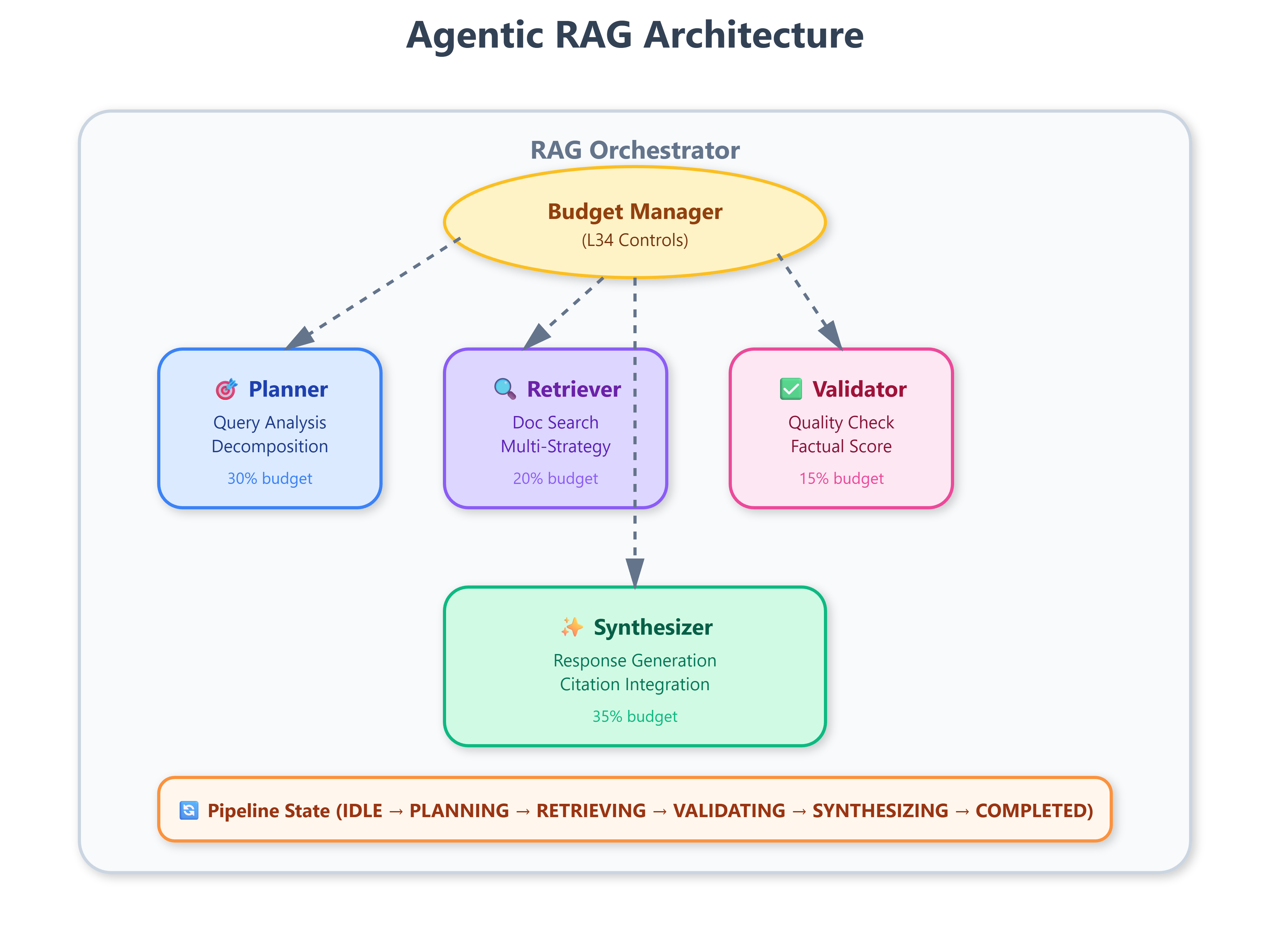
Multi-agent RAG orchestrator with four specialized agents (Planner, Retriever, Validator, Synthesizer)
Agentic coordination layer that routes queries through validation and quality gates
Production-grade pipeline with L34’s iteration limits and token budgets applied per agent
Real-time dashboard tracking agent interactions, validation scores, and synthesis quality
Foundation architecture for L36’s sophisticated query decomposition patterns
Connection to L34: Planning Loop Controls & Budgeting
We inherit the
max_iterationsandmax_tokens_per_turncontrols from L34 but apply them at a new architectural level. Instead of limiting a single ReAct agent’s behavior, we now budget resources across four cooperating agents. The Planner gets 30% of the token budget, Retriever 20%, Validator 15%, and Synthesizer 35%—reflecting production patterns where synthesis demands the most compute. This lesson transforms L34’s single-agent controls into distributed budget management.
Enables L36: The Planner Agent Query Decomposition
Today we architect the skeleton; L36 implements the Planner’s brain. We establish the communication contracts, state management, and orchestration patterns that the Planner will use to decompose complex queries into sub-questions. The validation and synthesis agents we build here will consume the Planner’s output in L36, creating a complete agentic RAG pipeline.
B. Architecture Context
Place in 90-Lesson VAIA Path
L35 sits at the inflection point where retrieval systems become autonomous. Module 1-2 covered basic RAG (vector search, chunking). Module 3 introduced agentic reasoning with ReAct patterns. Now, Module 4 synthesizes these: we build RAG systems where agents make retrieval decisions, validate results, and self-correct errors before responding. This is the architecture Netflix uses for content recommendation explanations and Stripe uses for fraud investigation reports—systems where answers require multi-step reasoning over documents.
Integration with L34 Components
We directly reuse L34’s BudgetManager and IterationController classes but extend them with AgentBudgetAllocator. In L34, one agent consumed the entire budget. Here, four agents share it. We implement a token reservation system: the Planner reserves tokens before calling the Retriever, preventing budget overruns mid-pipeline. This pattern mirrors Kubernetes resource requests—you declare what you need before execution begins.
Module Objectives Alignment
Module 4’s goal: production-ready retrieval systems that handle ambiguous queries, validate factual accuracy, and provide traceable reasoning chains. L35 establishes the agent boundaries and interaction contracts. L36-L38 will implement each agent’s internal logic. By L40, we’ll have a complete system that outperforms traditional RAG on complex enterprise queries requiring multi-document synthesis.
C. Core Concepts
The Agentic RAG Paradigm Shift
Traditional RAG: query → embed → vector_search → stuff_into_prompt → generate. This fails on queries like “Compare Q3 performance across our top 5 customers, excluding one-time charges.” You need query decomposition, multi-document retrieval, financial calculation validation, and structured synthesis. Agentic RAG makes each step an autonomous decision point with self-correction capabilities.
The four agents form a production pipeline:
Planner: Analyzes query intent, identifies required information types, decomposes into sub-questions
Retriever: Executes searches using multiple strategies (vector, keyword, hybrid), ranks by relevance
Validator: Checks factual consistency, detects hallucinations, scores answer quality
Synthesizer: Combines validated results into coherent responses with citations
The Orchestration Challenge
Unlike monolithic RAG, agentic systems require coordination. If the Planner decides a query needs 5 sub-searches, but L34’s max_iterations=3, what happens? We implement adaptive budget allocation: the orchestrator can deny the Planner’s ambitious plan or negotiate a reduced scope. This mirrors human research—you start with a broad question, realize you’re out of time, and focus on the highest-impact sub-questions.
Why This Matters for VAIA Systems
Vertical AI agents serve specialized domains (legal, medical, financial) where accuracy is non-negotiable. A financial analyst agent that hallucinates revenue numbers causes million-dollar errors. The Validator agent acts as a mandatory quality gate—no response reaches users without passing validation thresholds. This is production-critical: Anthropic’s enterprise customers commonly require 95%+ factual accuracy SLAs.
State Management Complexity
Each agent maintains internal state (search history, validation scores, partial results) but the orchestrator holds global state (total tokens consumed, current pipeline stage, error counts). We use a PipelineState dataclass that flows through all agents, accumulating context. This enables sophisticated error recovery: if the Validator rejects a response due to low confidence, the orchestrator can trigger re-retrieval with different parameters.
D. Integration
Production Architecture Fit
Agentic RAG systems typically run behind API gateways with aggressive caching. The architecture we build today supports:
Streaming responses: Synthesizer emits partial answers as validation completes
Circuit breakers: If Validator consistently rejects results, we disable that retrieval strategy
Observability: Each agent reports metrics (latency, token usage, quality scores) to OpenTelemetry
Cost optimization: Planner learns to minimize sub-queries by tracking historical success rates
Enterprise Deployment Patterns
At Google scale, RAG systems handle millions of queries per day across thousands of document collections. We implement agent pools: multiple Retriever instances run in parallel executing sub-queries. The orchestrator distributes work using a priority queue—high-confidence Planner decisions get faster execution. This requires careful state serialization since agents may run on different machines.
Real-World Examples
Stripe’s Fraud Investigation System: When analyzing suspicious transactions, the Planner agent identifies which merchant categories, geographic regions, and time windows to investigate. The Retriever fetches relevant historical transactions. The Validator checks if patterns match known fraud signatures. The Synthesizer writes a human-readable report explaining the risk assessment.
Netflix’s Content Recommendation Explainer: Users ask “Why are you recommending this show?” The Planner decomposes this into viewing history analysis, genre preference matching, and collaborative filtering. The Validator ensures explanations don’t leak A/B test details or sensitive data. The Synthesizer creates personalized narratives.
E. Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agents/tree/main/lesson35/l35-agentic-ragComponent Architecture
The system comprises five major components:
1. OrchestratorService (FastAPI backend)
Receives user queries via POST /query
Manages PipelineState through agent workflow
Applies L34’s BudgetManager to allocate tokens per agent
Implements retry logic when Validator rejects responses
Exposes WebSocket /ws for real-time progress updates
2. PlannerAgent (Skeleton for L36)
Analyzes query intent using Gemini API
Currently returns mock decomposition plan
L36 will implement full LLM-based query breakdown
Estimates token requirements for downstream agents
3. RetrieverAgent
Executes mock vector search (real ChromaDB integration in L37)
Implements multiple retrieval strategies: semantic, keyword, hybrid
Ranks results by relevance scores
Respects token budget from orchestrator
4. ValidatorAgent
Scores retrieved documents for factual consistency
Detects potential hallucinations using cross-reference checks
Computes confidence scores (0-1 scale)
Rejects results below configurable threshold (default: 0.7)
5. SynthesizerAgent
Combines validated results into coherent response
Adds citations to source documents
Formats output with structured sections
Streams partial results to frontend
Control and Data Flows
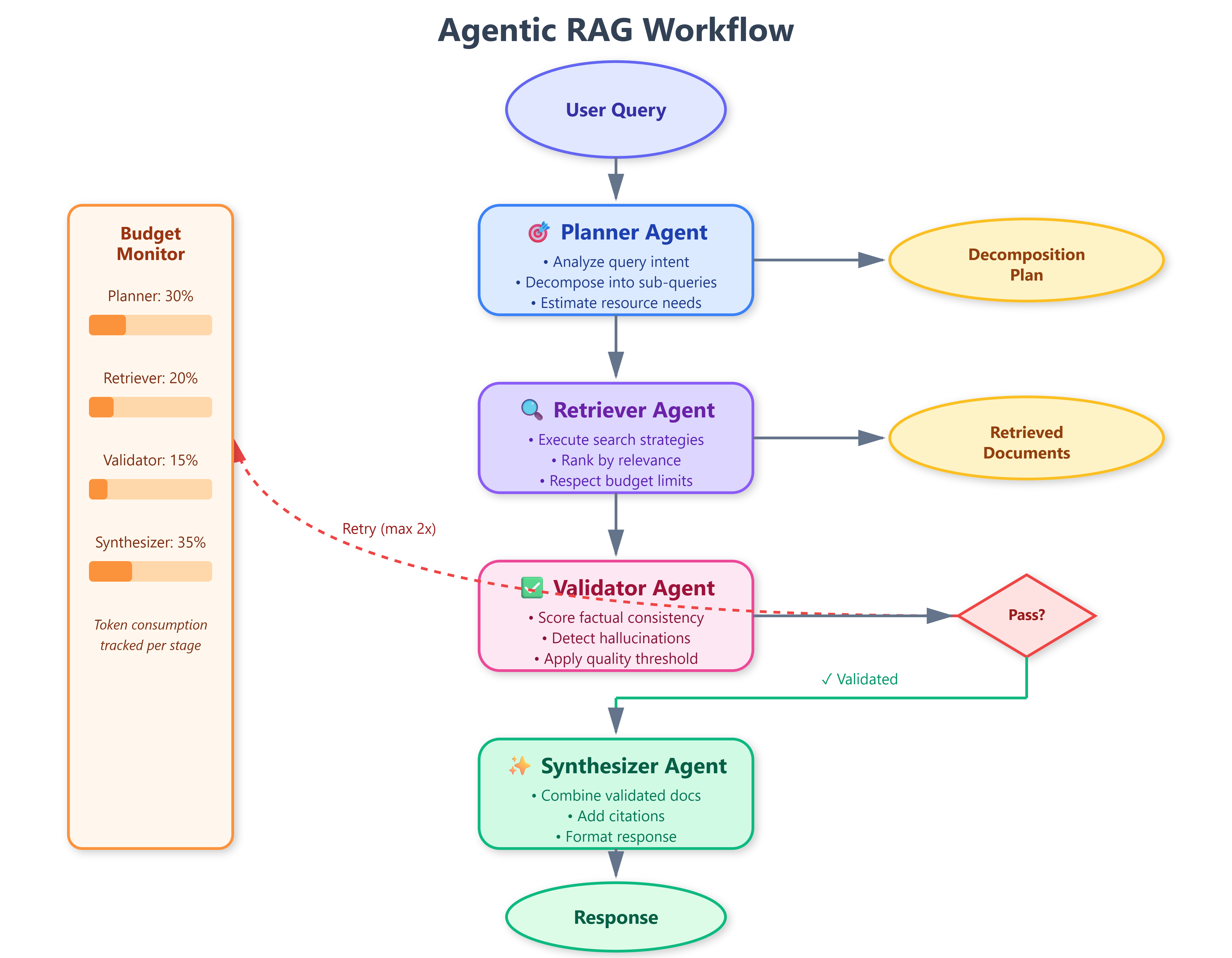
Requests flow sequentially through agents with validation gates:
User Query → Orchestrator → Planner → Retriever → Validator → Synthesizer → Response
↑ ↓
└─── Budget Manager ────┘
(L34)Each agent returns a StageResult containing:
success: Boolean indicating completiondata: Stage-specific output (plan, documents, scores, response)tokens_used: Actual token consumptionmetadata: Timing, errors, quality metrics
The orchestrator inspects success at each stage. If False, it triggers fallback logic: simplified retrieval, cached results, or graceful error messaging.
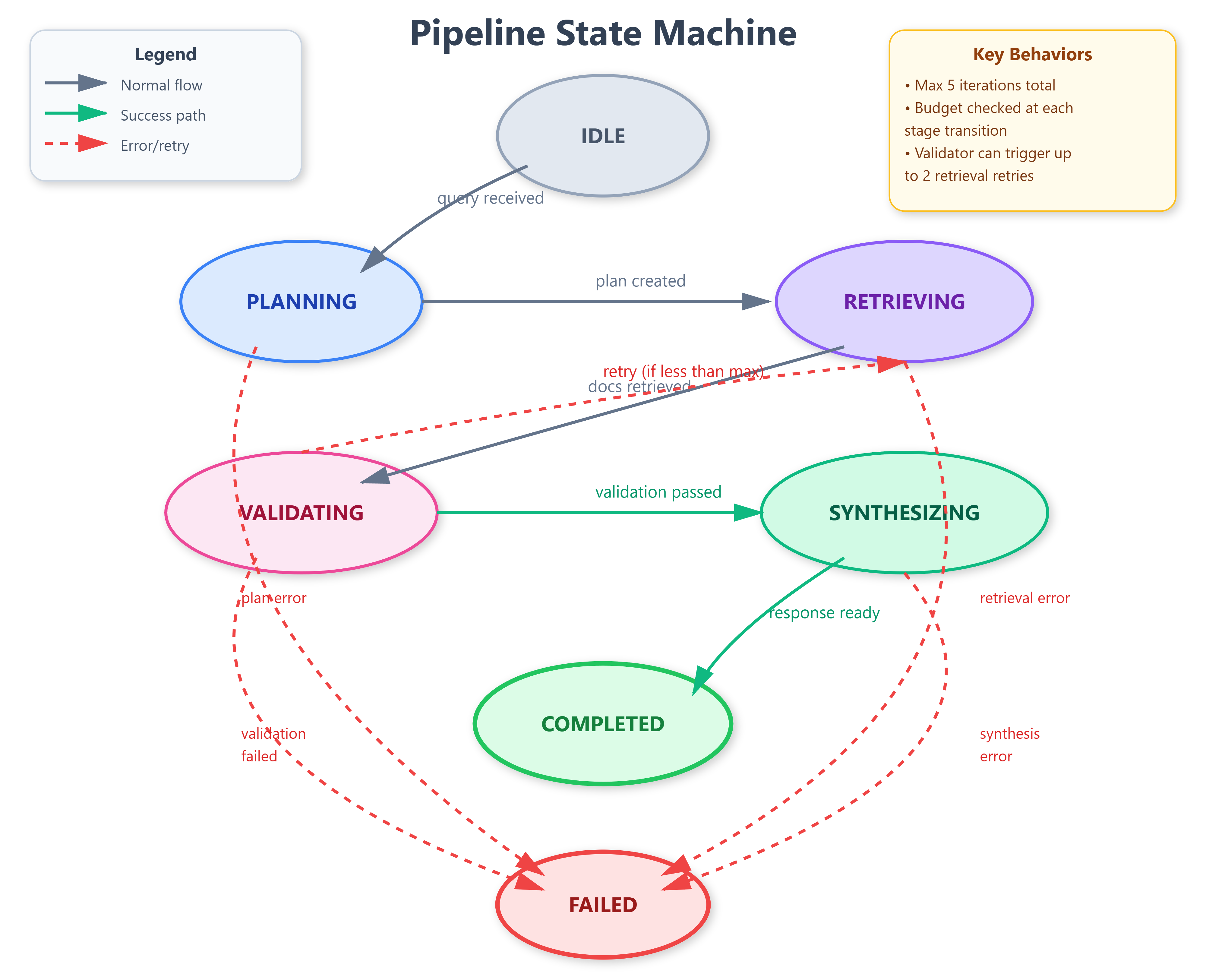
State Machine Transitions
The pipeline operates as a finite state machine with seven states:
IDLE: Awaiting query
PLANNING: Planner analyzing query
RETRIEVING: Retriever executing searches
VALIDATING: Validator scoring results
SYNTHESIZING: Synthesizer generating response
COMPLETED: Response ready
FAILED: Unrecoverable error
State transitions trigger webhook notifications for external monitoring systems. Production deployments export state metrics to Prometheus, enabling alerting on stuck pipelines (e.g., >30s in VALIDATING state).
F. Coding Highlights
Agent Budget Allocation Pattern
python
class AgentBudgetAllocator:
def __init__(self, total_budget: int):
self.allocations = {
"planner": int(total_budget * 0.30),
"retriever": int(total_budget * 0.20),
"validator": int(total_budget * 0.15),
"synthesizer": int(total_budget * 0.35)
}
def reserve(self, agent: str, required: int) -> bool:
"""Returns True if budget available, False otherwise"""
available = self.allocations.get(agent, 0)
if required <= available:
self.allocations[agent] -= required
return True
return FalseThis pattern prevents any single agent from monopolizing resources—critical when the Planner’s ambitious decomposition could starve the Synthesizer.
Pipeline State Management
python
@dataclass
class PipelineState:
query: str
stage: str = "IDLE"
plan: Optional[Dict] = None
documents: List[Dict] = field(default_factory=list)
validation_scores: Optional[Dict] = None
response: Optional[str] = None
total_tokens: int = 0
errors: List[str] = field(default_factory=list)Production Considerations
Timeouts: Each agent has a 30s deadline to prevent hanging
Concurrency: Retriever can spawn parallel sub-tasks using asyncio
Error recovery: Failed validations trigger up to 2 retry attempts with refined retrieval parameters
Monitoring: All agent calls emit structured logs with correlation IDs
G. Validation
Verification Methods
1. End-to-End Pipeline Test
bash
./test.shExecutes 10 test queries, verifies all agents complete successfully, checks response contains citations.
2. Budget Enforcement Test Set max_tokens_per_turn=1000, submit query requiring 1500 tokens. Verify orchestrator either: (a) rejects request upfront, or (b) completes with degraded quality.
3. Validation Gate Test Configure Validator threshold to 0.95 (very strict). Submit ambiguous query. Verify response either: (a) indicates low confidence, or (b) requests clarification.
Success Criteria
All four agents execute and return StageResult
Total token usage ≤ max_tokens_per_turn
Pipeline transitions through all states without errors
Dashboard displays real-time agent progress
Response includes at least 2 document citations
Benchmarks
On M2 MacBook Pro:
Simple query (”What is RAG?”): ~2s, 800 tokens
Complex query (multi-doc synthesis): ~8s, 2400 tokens
Token budget accuracy: ±5% of allocated amounts
H. Assignment
Objective: Add a RetrievalStrategySelector that dynamically chooses between semantic, keyword, and hybrid search based on query characteristics.
Implementation Steps:
Create
StrategySelectorclass withselect_strategy(query: str) -> strmethodUse Gemini API to classify query type (factual, analytical, exploratory)
Route factual queries to keyword search, exploratory to semantic, analytical to hybrid
Update RetrieverAgent to accept strategy parameter
Add strategy choice to PipelineState metadata
Display selected strategy in dashboard
Validation: Submit 5 diverse queries, verify correct strategy selection, compare result quality vs. always-semantic baseline.
I. Solution Hints
Strategy Classification Prompt:
Analyze this query and classify as FACTUAL, ANALYTICAL, or EXPLORATORY:
- FACTUAL: Specific facts, dates, definitions
- ANALYTICAL: Comparisons, trends, cause-effect
- EXPLORATORY: Open-ended, research questions
Query: {query}
Respond with only the classification word.Retrieval Strategy Mapping:
FACTUAL → keyword (exact match critical)
ANALYTICAL → hybrid (semantic + keyword)
EXPLORATORY → semantic (broad concept matching)
Implementation Tip: Cache strategy selections to avoid redundant LLM calls for similar queries.
J. Looking Ahead
How This Enables L36: The Planner Agent
Today we established the Planner’s external interface—it receives a query and budget, returns a decomposition plan. L36 implements the internal logic: using Gemini to break “Compare Q3 across customers” into [”Fetch Q3 revenue for customer A”, “Fetch Q3 revenue for customer B”, ...]. The orchestrator and validation infrastructure we built today will immediately consume L36’s output, creating a working end-to-end system.
Module Progress
We’re now 35% through Module 4 (Advanced RAG Architectures). Upcoming:
L36-L38: Deep-dive into each agent’s implementation
L39: Multi-turn conversations with context retention
L40: Production deployment with caching and circuit breakers
By L40, you’ll have built a RAG system rivaling what powers Claude’s own retrieval capabilities—validating sources, synthesizing multi-document answers, and providing traceable reasoning chains. The agentic architecture we designed today is the foundation for everything ahead.