[A] Today’s Build
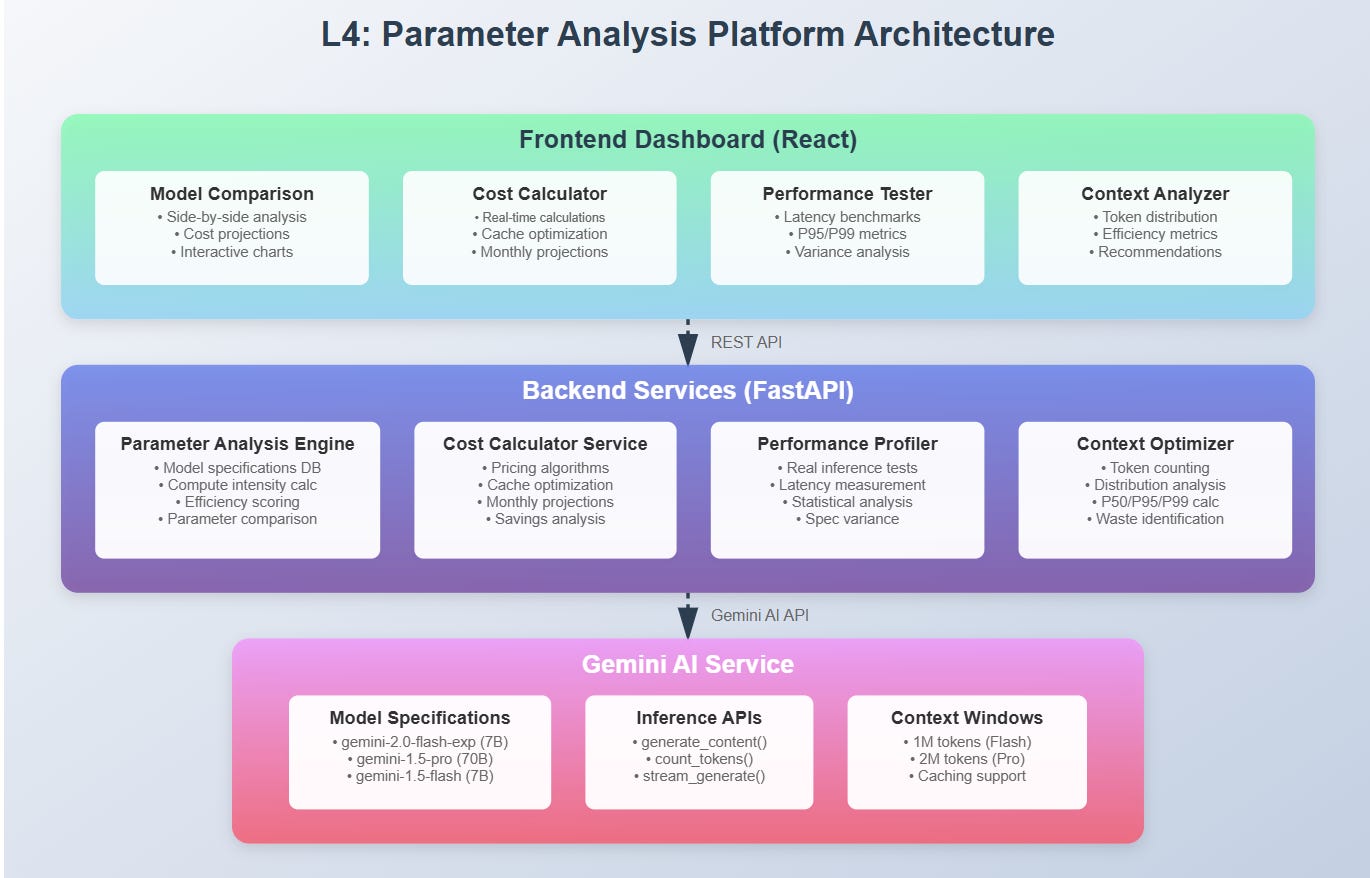
LLM Parameter Analysis Platform - Real-time system analyzing the critical relationship between model parameters, performance, and cost:
Parameter Intelligence Engine: Analyzes parameter counts (7B to 405B+), context windows (4K to 2M tokens), and training data scale
Dynamic Cost Calculator: Real-time pricing across inference modes with per-token breakdown and monthly projections
Performance Profiler: Measures latency, throughput, and quality trade-offs at different parameter scales
Interactive Comparison Dashboard: Side-by-side analysis of model configurations with production cost implications
Context Window Optimizer: Identifies optimal context usage patterns based on task requirements
Building on L3: Leverages the Transformer architecture understanding to explain why parameter count directly impacts attention head capacity, layer depth, and ultimately model capability.
Enabling L5: Creates the analytical foundation for comparing GPT-5, Gemini 2.0, Claude 3.7, and Llama 3.1 with quantified metrics rather than marketing claims.
[B] Architecture Context
Position in 90-Lesson VAIA Path: Module 1 (Foundational Concepts) → Lesson 4 of 10
After mastering Transformer mechanics in L3, we now quantify how architectural choices (layers, heads, parameters) translate into production realities: cost, speed, and capability. This lesson bridges theoretical understanding with operational decision-making.
Integration with L3: Uses the Transformer block implementation to demonstrate how increasing d_model from 768 to 12,288 or expanding attention heads from 12 to 96 multiplies computational requirements exponentially. Every parameter in those attention matrices has inference cost.
Module Objectives Alignment: Completes the foundation trilogy—L2 established agent patterns, L3 revealed internal mechanics, L4 quantifies operational impact. Students now possess the complete context for intelligent model selection in enterprise deployments.