
Are you just starting on AI, feeling missed the bus ? start out fresh here… Master AI & ML in 180 Days. Hands-on. From Scratch.
🚀 Join here: https://aieworks.substack.com/s/ai-and-ml-course
Highlights
You cannot improve what you cannot measure. In production RAG systems, evaluation isn’t a post-deployment concern — it’s the engineering discipline that separates systems that hallucinate under load from ones that earn trust.
What we build in this lesson:
A Ragas-powered evaluation pipeline wired to Gemini as the LLM judge, measuring faithfulness, answer relevancy, context recall, and context precision
A TestDataset Generator that auto-synthesizes evaluation questions from your existing corpus — no manual labeling required
A MetricsEngine implementing both automated Ragas scoring and a custom Gemini-judge path for metrics Ragas can’t cover
A live evaluation dashboard (React + Recharts) visualizing per-metric scores, per-question breakdowns, and regression trends across evaluation runs
A benchmark harness that gates pipeline changes — if faithfulness drops below threshold, deployment is blocked
Connection to L43
L43 delivered a fully integrated Agentic RAG pipeline: Planner → Retriever → Validator → Synthesizer, with internal self-correction loops and trace metadata at every step. That pipeline is exactly what we evaluate here.
The critical integration point: L43’s pipeline emits structured traces —
question,retrieved_contexts,answer,validation_status,correction_count. L44’s evaluator consumes these traces directly. You don’t need to re-run queries; every L43 execution produces evaluation-ready artifacts.
This is the pattern elite RAG teams use: continuous evaluation as a side effect of inference, not as a separate offline batch job.
Enables L45
L45 (Project 3: Autonomous Research Agent) demands a system you can trust with open-ended research tasks. Without the evaluation foundation from L44, you’re flying blind. What L44 provides L45:
Regression gate: Any change to the research agent’s retrieval or synthesis strategy runs through L44’s benchmark harness before merging
Quality floor: The evaluation pipeline defines the minimum acceptable faithfulness and relevancy scores for the research domain
Dataset factory: L44’s synthetic test generator seeds L45’s research benchmark suite automatically
Architecture Context
L44 sits at the quality assurance layer of the VAIA stack. In the 90-lesson path, it closes the Module 4 loop:
L41 (ReAct Patterns) → L42 (Multi-step RAG) → L43 (E2E Pipeline) → L44 (Evaluation) → L45 (Project 3)At enterprise scale, this evaluation layer is non-negotiable. Netflix’s recommendation systems, Stripe’s fraud detection, and Google’s search pipelines all maintain continuous evaluation suites that run on every model or retrieval change. VAIA systems follow the same discipline.
Core Concepts
The Four Pillars of RAG Evaluation
RAG evaluation has a specific challenge: unlike classification tasks, there’s no single ground truth label. The answer can be correct but unfaithful (hallucinated facts beyond the context), or faithful but irrelevant (answers the wrong question). Four metrics triangulate system health:
1. Faithfulness — Does the answer contain only claims supported by the retrieved context?
This is the anti-hallucination metric. A faithfulness score of 1.0 means every claim in the answer can be traced back to a retrieved passage. Score 0.6 means ~40% of claims are invented. Implementation: decompose the answer into atomic claims, then check each claim against the context using Gemini as judge.
2. Answer Relevancy — Is the answer actually responsive to the question asked?
A system can be faithful (only says things in the context) but still irrelevant (answers a different question). Relevancy is measured by reverse-engineering: generate candidate questions from the answer, then measure semantic similarity to the original question.
3. Context Recall — Did the retriever surface the passages needed to answer correctly?
Requires ground truth. Decompose the reference answer into claims, check what fraction can be attributed to retrieved context. Low recall = the retriever is missing critical passages.
4. Context Precision — Are the top-k retrieved passages actually relevant?
High recall retriever that returns 20 chunks including 18 irrelevant ones has terrible precision. This measures signal-to-noise in your retrieval step.
The LLM-as-Judge Pattern
Ragas uses an LLM (Gemini in our case) to make evaluation judgments. This unlocks scalable, nuanced evaluation without expensive human annotation. The key insight: the evaluator LLM needs to be as capable or more capable than the generation LLM. Using a weaker judge produces misleading scores.
In 2025, Gemini 1.5 Pro as judge with structured JSON output provides reliable, reproducible evaluations when you combine it with:
Temperature 0 for determinism
Explicit rubric in the prompt (not just “is this good?”)
Multi-sample averaging for statistical stability
Evaluation Dataset Construction
The most underrated skill in RAG evaluation: synthetic test set generation. Manually labeling 100 QA pairs takes days. Ragas’s TestsetGenerator creates evaluation datasets from your document corpus automatically by:
Sampling passages from your ChromaDB corpus
Generating questions of varying complexity (simple, multi-hop, conditional)
Producing reference answers from the passage content
Filtering for diversity and difficulty distribution
Integration
Production Architecture Fit
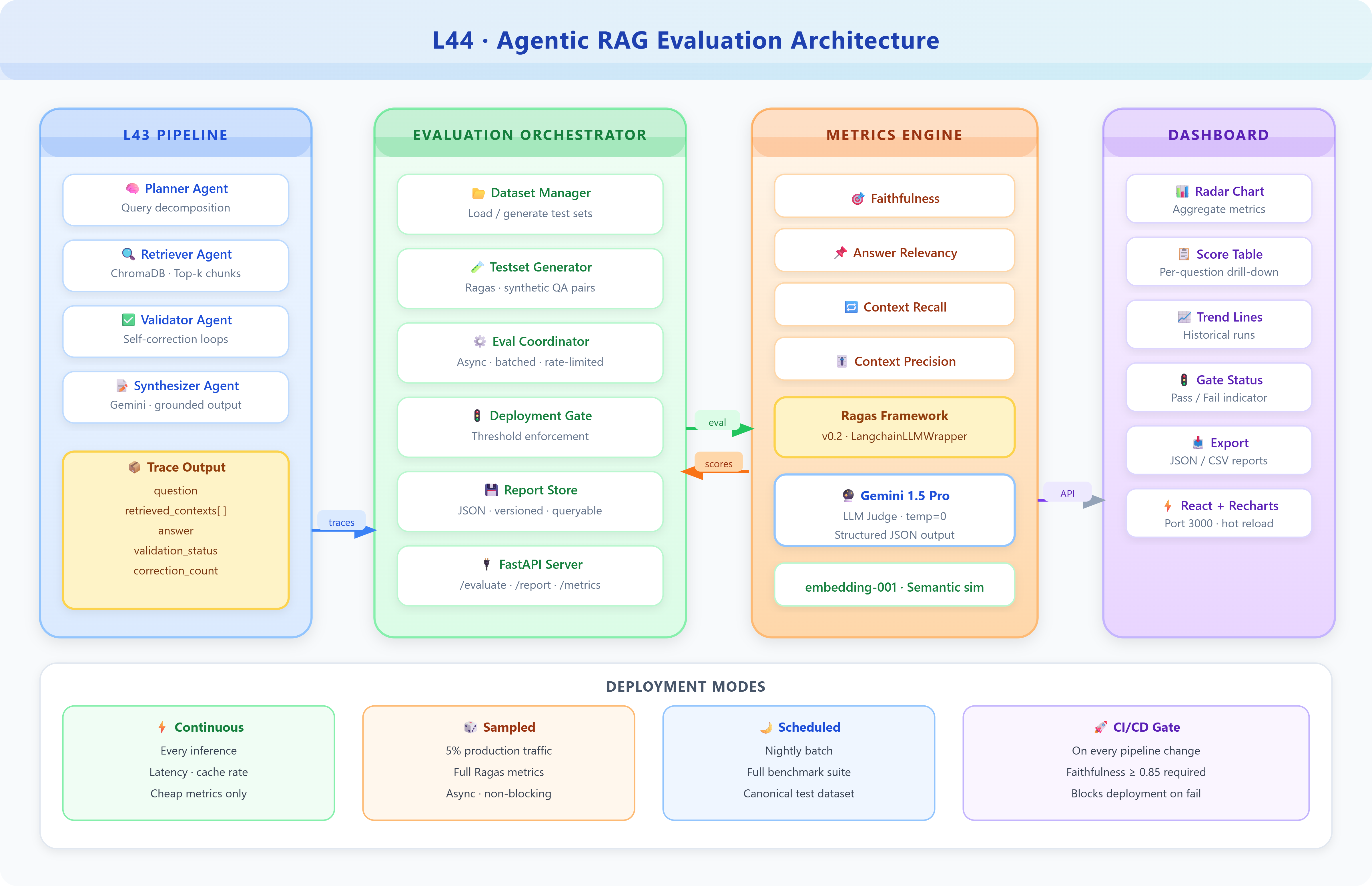
In production, the evaluation pipeline runs in three modes:
Continuous (every inference): Cheap metrics only — answer length, retrieval latency, cache hit rate
Sampled (5% of production traffic): Full Ragas metrics on a random sample
Scheduled (nightly): Full benchmark suite against the canonical test dataset
Workflow and Dataflow
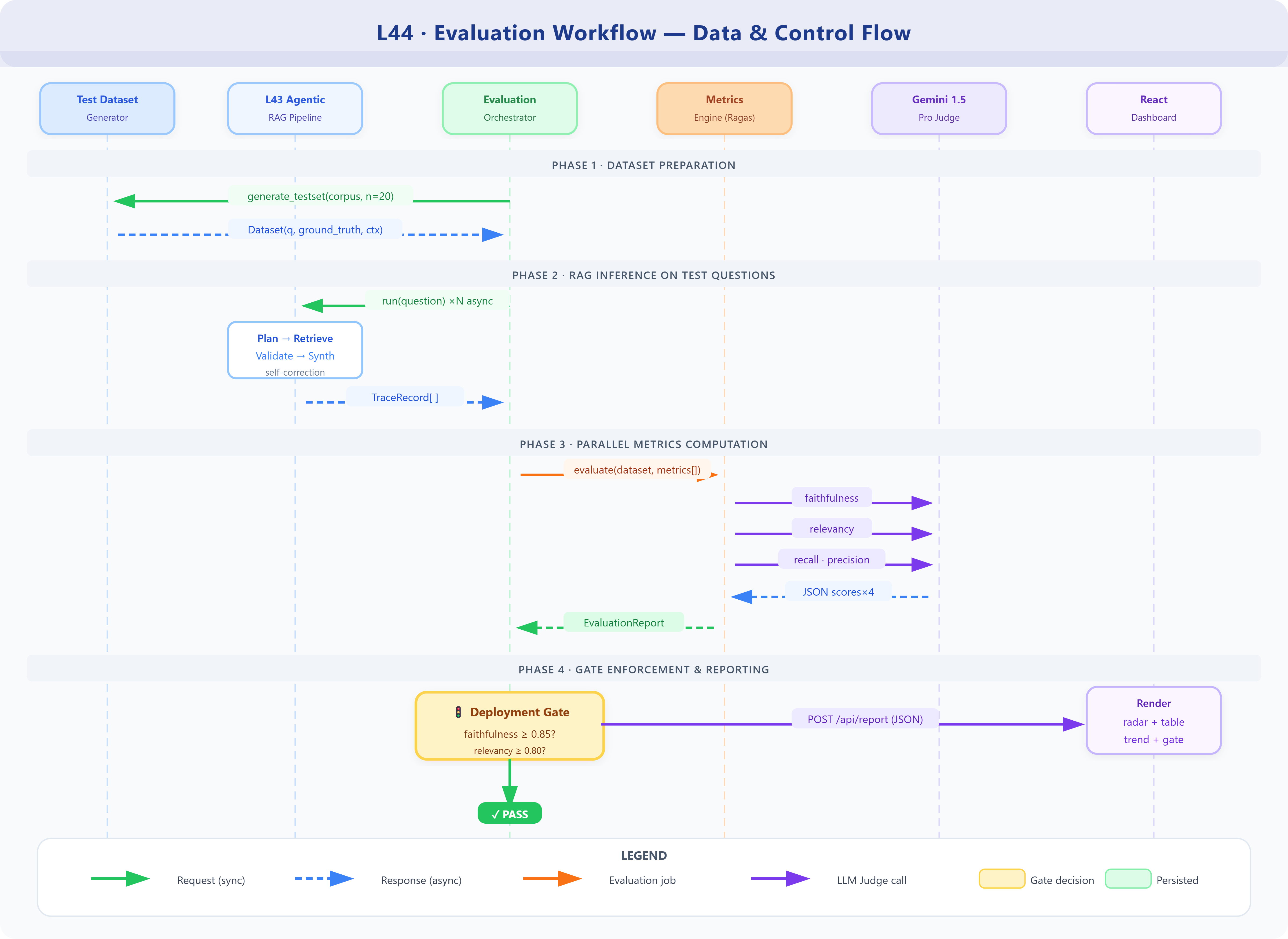
The evaluation workflow extends L43’s pipeline trace: every time the Agentic RAG system processes a question, it stores a structured trace. The evaluator processes these traces asynchronously, computing metrics in parallel, and writing scores to the metrics store. The dashboard queries the metrics store for visualization.
State Machine
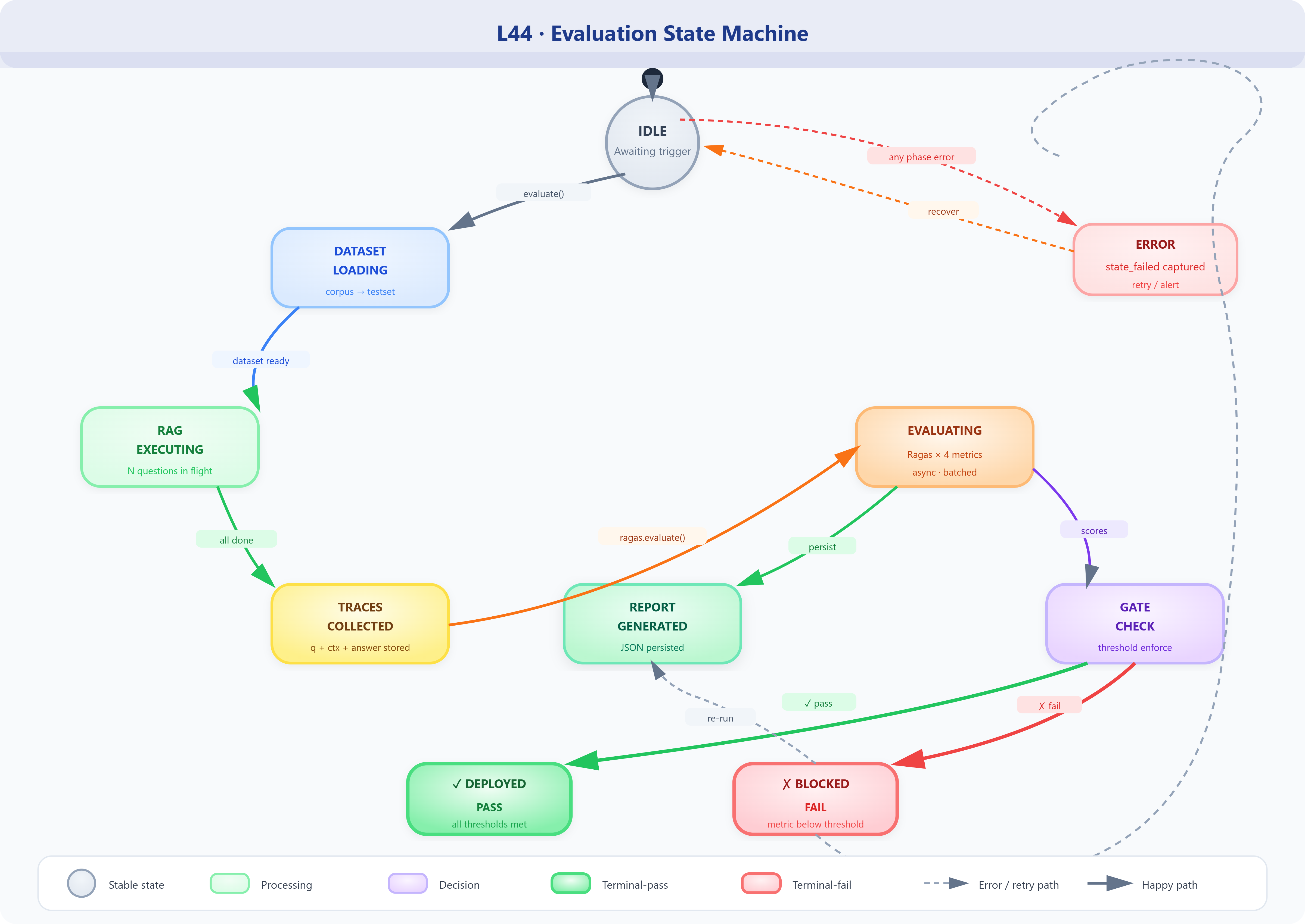
The evaluator moves through well-defined states: IDLE → DATASET_LOADING → RAG_EXECUTING → TRACES_COLLECTED → EVALUATING → SCORED → REPORT_GENERATED. Failure at any state triggers ERROR with the failed state recorded for debugging.
Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agents/tree/main/lesson44/l44-rag-evaluation
Component Architecture
The evaluation system has four primary components:
TestDatasetGenerator wraps Ragas’s TestsetGenerator with a Gemini LLM and GoogleGenerativeAI embeddings. It takes the ChromaDB corpus from L43 and produces a Dataset object with columns: question, ground_truth, contexts, answer.
MetricsEngine configures four Ragas metrics with the shared Gemini judge, runs ragas.evaluate(), and returns per-metric aggregate scores plus per-question scores for drill-down analysis.
EvaluationOrchestrator sequences the pipeline: load or generate dataset → execute Agentic RAG on each question → collect traces → run MetricsEngine → persist report → notify dashboard.
EvaluationDashboard (React) polls the /api/evaluations/latest endpoint and renders: a radar chart of aggregate metrics, a table of per-question scores with drill-down, a historical trend line, and a pass/fail gate indicator.
Key Configuration Patterns
python
# Gemini as Ragas judge — the 2025-correct approach
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
judge_llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
google_api_key=GEMINI_API_KEY,
temperature=0, # determinism for reproducible evals
convert_system_message_to_human=True # Gemini requirement
)
judge_embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001",
google_api_key=GEMINI_API_KEY
)
ragas_llm = LangchainLLMWrapper(judge_llm)
ragas_embeddings = LangchainEmbeddingsWrapper(judge_embeddings)Faithfulness Deep-Dive
python
# Custom faithfulness scorer using Gemini directly
# Use when Ragas is unavailable or for audit trails
FAITHFULNESS_PROMPT = """
You are evaluating RAG system faithfulness.
QUESTION: {question}
RETRIEVED CONTEXT: {context}
GENERATED ANSWER: {answer}
Task: Extract all factual claims from the ANSWER. For each claim, determine if it is
directly supported by the RETRIEVED CONTEXT.
Respond with JSON only:
{{
"claims": [
{{"claim": "...", "supported": true/false, "evidence": "quote from context or null"}}
],
"faithfulness_score": 0.0-1.0,
"reasoning": "..."
}}
"""Threshold-Gated Deployment
python
EVALUATION_THRESHOLDS = {
"faithfulness": 0.85, # < 15% hallucination tolerance
"answer_relevancy": 0.80, # 80% answers must be on-topic
"context_recall": 0.75, # retriever must find 75%+ of needed info
"context_precision": 0.70, # 70%+ retrieved chunks must be relevant
}
def gate_deployment(report: EvaluationReport) -> DeploymentDecision:
failures = {
metric: score
for metric, score in report.aggregate_scores.items()
if score < EVALUATION_THRESHOLDS[metric]
}
return DeploymentDecision(
approved=len(failures) == 0,
blocking_metrics=failures,
report_id=report.id
)Coding Highlights
Pattern 1: Parallel metric evaluation — Don’t run faithfulness, relevancy, recall, precision sequentially. Each makes independent LLM calls. Use asyncio.gather() across metrics for 4x throughput improvement.
Pattern 2: Batch evaluation with rate limiting — Ragas makes multiple LLM calls per question. With 100 test questions, you’ll hit Gemini rate limits. Implement a token bucket: max 10 concurrent evaluations, 1-second sleep between batches.
Pattern 3: Evaluation caching — Question+context+answer triplets that haven’t changed don’t need re-evaluation. SHA-256 hash the triplet, cache scores in Redis. This makes re-runs after code-only changes nearly instant.
Pattern 4: Ground truth tiers — Not all questions need ground truth. Faithfulness and answer relevancy are reference-free (no ground truth needed). Context recall and answer correctness require ground truth. Structure your test dataset accordingly: 100% coverage for reference-free metrics, 30% gold-labeled for reference-required metrics.
Validation
Success Criteria
Evaluation pipeline completes 20-question test suite in under 3 minutes
All four Ragas metrics produce scores (no NaN/null values)
Dashboard renders radar chart and per-question table
Deployment gate correctly blocks when faithfulness < 0.85
Synthetic dataset generator produces diverse question types
Benchmarks (Expected on L43’s corpus)
MetricTargetAlert ThresholdFaithfulness≥ 0.85< 0.70Answer Relevancy≥ 0.80< 0.65Context Recall≥ 0.75< 0.60Context Precision≥ 0.70< 0.55
Assignment
Extend L44: Implement a comparative evaluation mode that runs the same test dataset through two pipeline configurations (e.g., different chunk sizes or top-k values) and produces a side-by-side comparison report. Which configuration wins on which metrics? Add a “winner” indicator to the dashboard.
Build toward L45: The Autonomous Research Agent (L45) will need domain-specific evaluation. Create a custom faithfulness metric variant called CitationFaithfulness that checks whether the answer’s inline citations match the source passages — critical for research output trustworthiness.
Solution Hints
Use
ragas.testset.TestsetGeneratorwithsimple,reasoning, andmulti_contextevolution types for diverse question coverageFor the comparative mode, run
evaluate()twice with the sameDatasetbut swap theanswercolumn; keepcontextsandground_truthidenticalCitationFaithfulness: parse[1],[2]style citations from the answer, extract corresponding context chunks, score using the standard faithfulness rubric on each cited pair
Looking Ahead
L45 builds the Autonomous Research Agent — a VAIA system that plans multi-step research tasks, retrieves from heterogeneous sources, and produces structured reports with citations. The evaluation infrastructure from L44 is its quality backbone: every iteration of the research agent runs through the benchmark harness before being promoted.
Specifically, L45 inherits:
The
EvaluationPipelineas its CI/CD quality gateThe
TestDatasetGeneratorseeding its domain-specific benchmarkThe
MetricsEngineextended withCitationFaithfulnessfor research output validation
Module 4 progress: L44 closes the evaluation loop on agentic RAG. You now have end-to-end capability: build (L41-L43) → evaluate (L44) → deploy with confidence (L45+). This is the complete inner loop of production VAIA engineering.
This is where most people drop off.
Building is easy. Evaluating is the real work.
Once you add loops like this with:
Vertex AI
Gemini
you’re not building tools anymore, you’re building systems.
That shift is underrated.
Exploring it deeper here: https://shorturl.at/J6Wwh