Highlights
What We Build
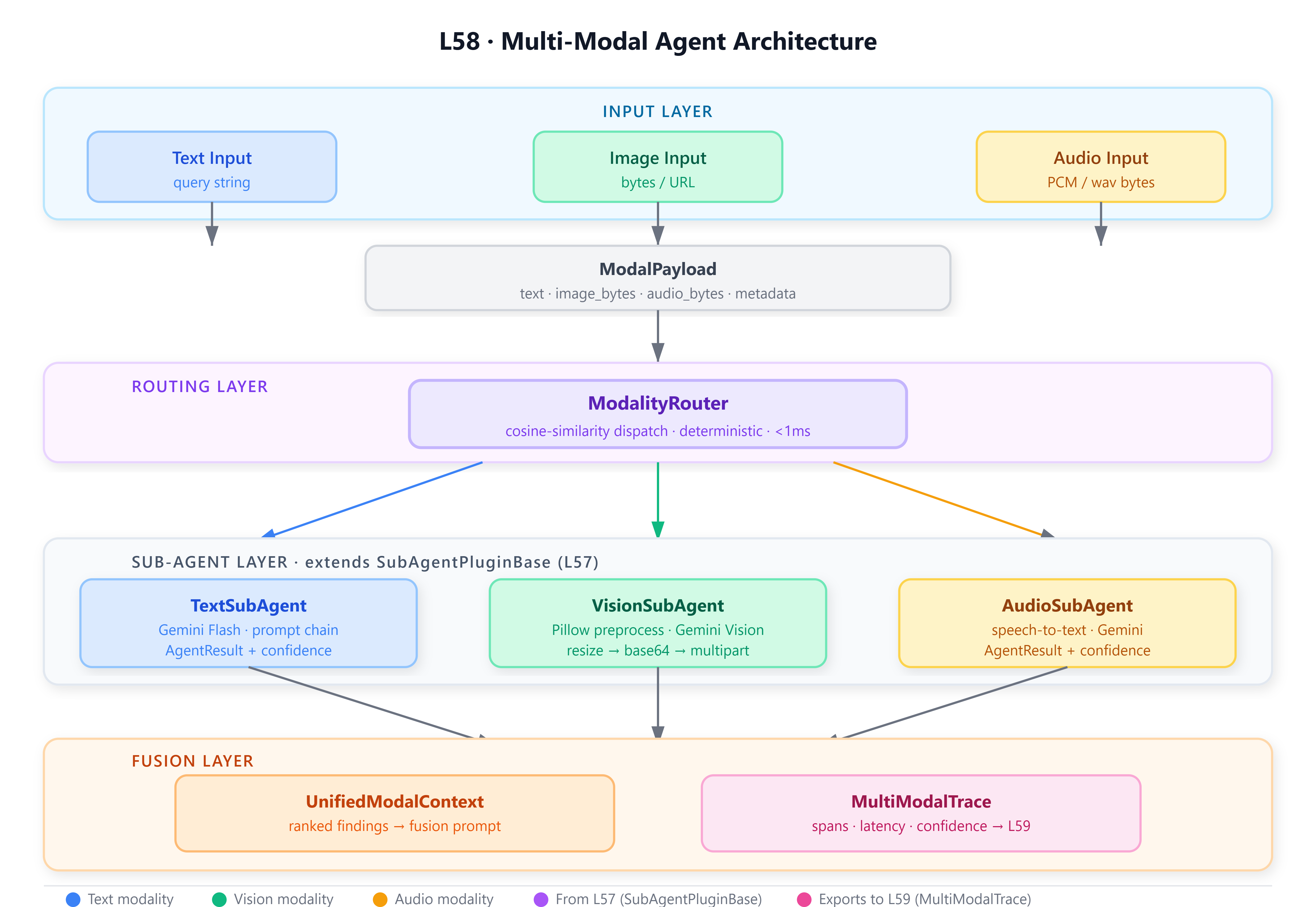
A
MultiModalAgentthat accepts simultaneous text, image, and audio inputs and produces a single unified response through coordinated sub-agents.A deterministic
ModalityRouterthat scores and assigns inputs to specialized sub-agents using cosine similarity on modality feature vectors — no LLM in the hot path.A
VisionSubAgentbacked by Gemini’s vision API, with a Pillow-powered preprocessing pipeline that normalizes, resizes, and annotates images before they reach the model.A
UnifiedModalContextdataclass that aggregates partial results across modalities into a fused representation consumed by the orchestrator for final synthesis.A
MultiModalTracestructure embedding execution spans per modality — the direct logging substrate consumed by L59’s evaluation harness.
Connection to L57 (Sub-Agent Architectures)
L57 introduced
SubAgentPluginBaseandSubAgentOrchestrator— a pattern where an agent’s “tool” is itself another agent. L58 extends this directly:VisionSubAgent,TextSubAgent, andAudioSubAgentall inheritSubAgentPluginBase. TheMultiModalAgentextendsSubAgentOrchestrator, adding modality dispatch logic on top of nested execution. EveryAgentResultcarries theconfidencefield introduced in L57 — the router uses it for inter-modal weighting during fusion.
Enables L59 (MAS Evaluation & Debugging)
MultiModalTraceproduced here carries structured spans —modality,latency_ms,token_count,confidence,error— exactly what L59’s loguru-based tracer will consume. The per-modality timing hooks placed inLoggableSubAgent(which all sub-agents here extend) are the profiling attachment points L59 exploits without modifying production code.
Architecture Context
This lesson sits at the intersection of two curriculum threads: the sub-agent composition pattern introduced in L46–L57, and the evaluation infrastructure that begins in L59. Multi-modal capability is not a feature addition on top of agents — it is a structural redesign of how inputs are represented, routed, and fused.
In the 90-lesson VAIA arc, L58 completes Module 6’s capstone skill: building agents that mirror the sensory diversity of real enterprise inputs. Production VAIAs in healthcare, legal, manufacturing, and field operations routinely receive mixed-modality payloads — a voice memo attached to a photo of a damaged component, a scanned invoice alongside a typed query. Handling these in a unified pipeline without modality-specific silos is the core engineering challenge this lesson solves.
The architecture integrates with Module 5’s orchestration patterns (L55 Google ADK, L56 Semantic Kernel) through the SubAgentPluginBase interface — any modality sub-agent can be registered in either framework’s plugin registry without modification.