Lesson 6: Interacting with LLM APIs - Production-Grade Integration Patterns
[A] Today’s Build
We’re building an enterprise-grade LLM API client framework that handles:
Secure credential management with environment-based configuration and rotation support
Intelligent rate limiting using token bucket algorithm with distributed state
Production-grade retry logic with exponential backoff and circuit breaker patterns
Cost tracking and quota management with real-time usage monitoring
Request/response observability with structured logging and latency metrics
This builds directly on L5’s model selection framework by implementing the API layer that actually communicates with Gemini AI. While L5 helped you choose the right model, L6 teaches you how to interact with it reliably at scale.
This implementation prepares you for L7’s prompt engineering by establishing a robust API foundation that handles authentication, errors, and resource management—letting you focus on prompt design rather than infrastructure concerns.
[B] Architecture Context
In the 90-lesson VAIA curriculum, L6 sits at a critical junction: you’ve selected your models (L5), and now you need production-ready communication infrastructure before advancing to prompt engineering (L7) and agent orchestration (L8-L12).
Integration with L5: We import the model selection logic from L5 and enhance it with actual API connectivity. The ModelConfig class from L5 now includes rate limits, costs per token, and timeout configurations.
Module Objectives: This lesson completes Module 1 (Foundations) by delivering the final piece: reliable API communication. You’ll build patterns used by production systems handling millions of API calls daily.
Progressive Skill Building: By mastering API interaction patterns here, you’ll be prepared for L7’s prompt engineering, L8’s streaming responses, and eventually L15’s multi-model orchestration.
[C] Core Concepts
The Hidden Complexity of “Simple” API Calls
Most tutorials show you requests.post() and call it done. Production systems need:
Token Budget Management: Gemini enforces requests per minute (RPM) and tokens per minute (TPM). Naive implementations hit limits instantly under load. We implement a token bucket algorithm that tracks both RPM and TPM with millisecond precision.
Exponential Backoff with Jitter: Network failures happen. The difference between amateur and professional: amateurs retry immediately (thundering herd), professionals use exponential backoff with jitter (0.1s, 0.2s, 0.4s + random offset).
Circuit Breaker Pattern: When the API is down, stop hammering it. After 5 consecutive failures, open the circuit for 60 seconds. This protects both your quota and the downstream service.
Cost Attribution: Every API call costs money. Production systems track cost per request, per user, per feature. We implement real-time cost calculation using Gemini’s pricing: $0.075/1M input tokens, $0.30/1M output tokens (Gemini 1.5 Flash).
VAIA System Design Relevance
In enterprise VAIA systems, the API client is critical infrastructure. A poorly designed client causes:
Cascading failures: One slow request blocks all others (thread pool exhaustion)
Budget overruns: No visibility into token consumption leads to surprise bills
User frustration: No retry logic means transient failures become permanent errors
Our implementation uses:
Async I/O: Non-blocking calls with
asyncioandaiohttpfor 10x throughputConnection pooling: Reuse TCP connections (reduces latency by 50ms per request)
Request queuing: Graceful degradation under load with priority queues
Workflow, Dataflow, and State Changes
Request Flow:
Client submits request → Queue (priority-based)
Rate limiter checks token bucket → Allow/Throttle
API client sends request with auth headers
Response handler validates, retries on failure, logs metrics
Cost tracker updates usage counters
Response returned to client
State Transitions:
Circuit: CLOSED → OPEN (5 failures) → HALF_OPEN (60s timeout) → CLOSED (success)
Token bucket: Refills at configured rate (e.g., 1000 tokens/minute)
Request: QUEUED → PROCESSING → COMPLETED/FAILED/RETRYING
[D] VAIA Integration
Production Architecture Fit
In a production VAIA system, this API client sits between your agent logic and external LLM services:
Agent Orchestrator → API Client (L6) → Gemini AI
↓
Cost Tracker
Rate Limiter
Circuit BreakerNetflix Pattern: Netflix’s Hystrix library inspired our circuit breaker. When their recommendation service calls external APIs, they use similar patterns to prevent cascading failures.
Stripe Pattern: Stripe’s API clients track quota exhaustively. Every engineer can see real-time cost attribution for their features. We implement the same visibility.
Enterprise Deployment Patterns
Multi-Region Failover: Configure multiple Gemini endpoints (us-central1, europe-west1). If one region is degraded, automatically route to healthy regions.
Quota Pooling: In large organizations, centralize quota management. One team’s spike doesn’t exhaust the org-wide quota.
Audit Trail: Every API call is logged with request_id, user_id, cost, latency. Required for SOC2 compliance and debugging production incidents.
Real-World Examples
OpenAI’s ChatGPT: Handles 100M+ API calls/day. They use sophisticated rate limiting to prevent abuse while maintaining responsiveness. Our token bucket algorithm mirrors their approach.
Google’s Vertex AI: Enterprise customers get dedicated quota pools with SLA guarantees. We implement quota tracking that prepares you for similar enterprise requirements.
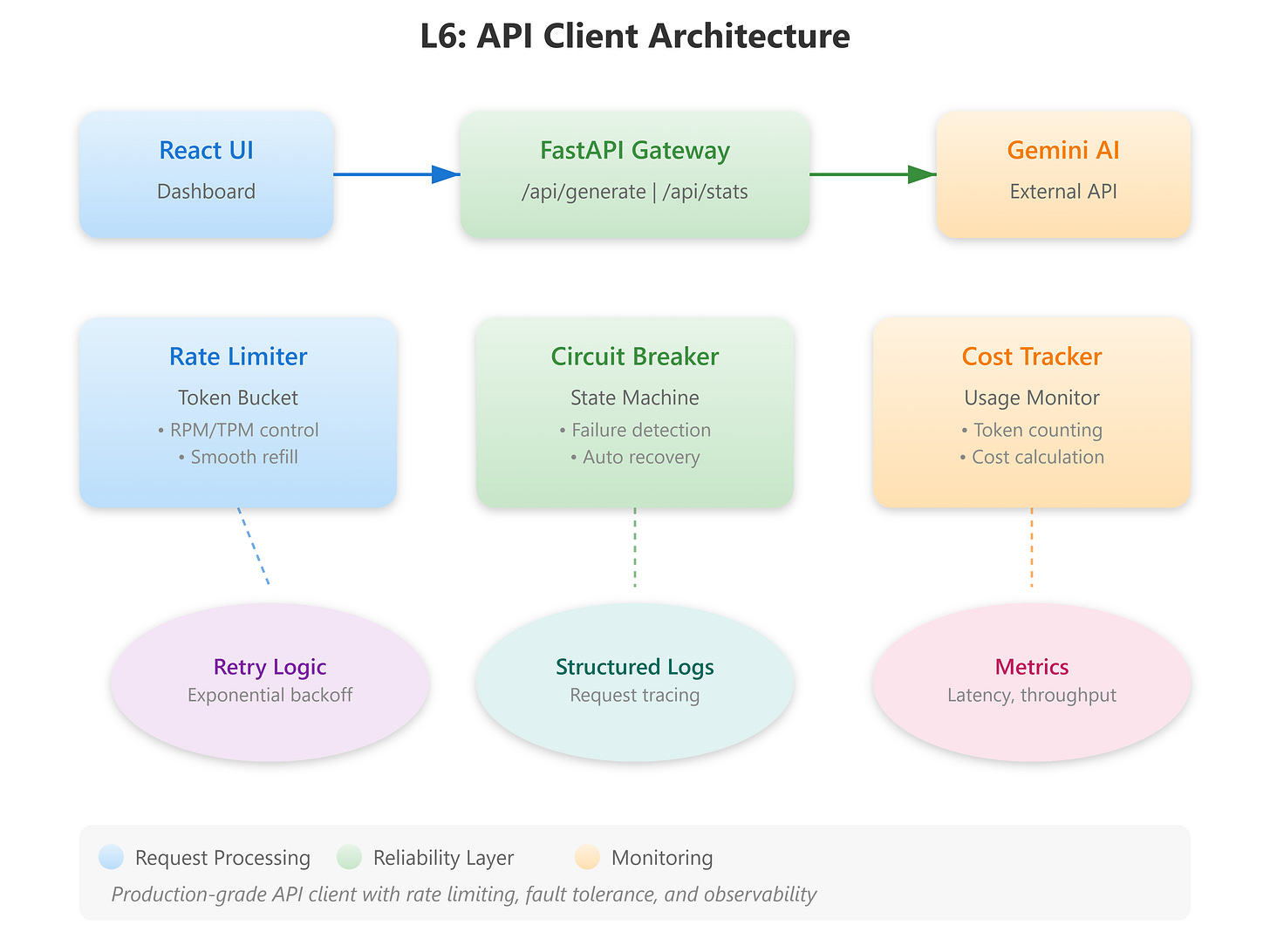
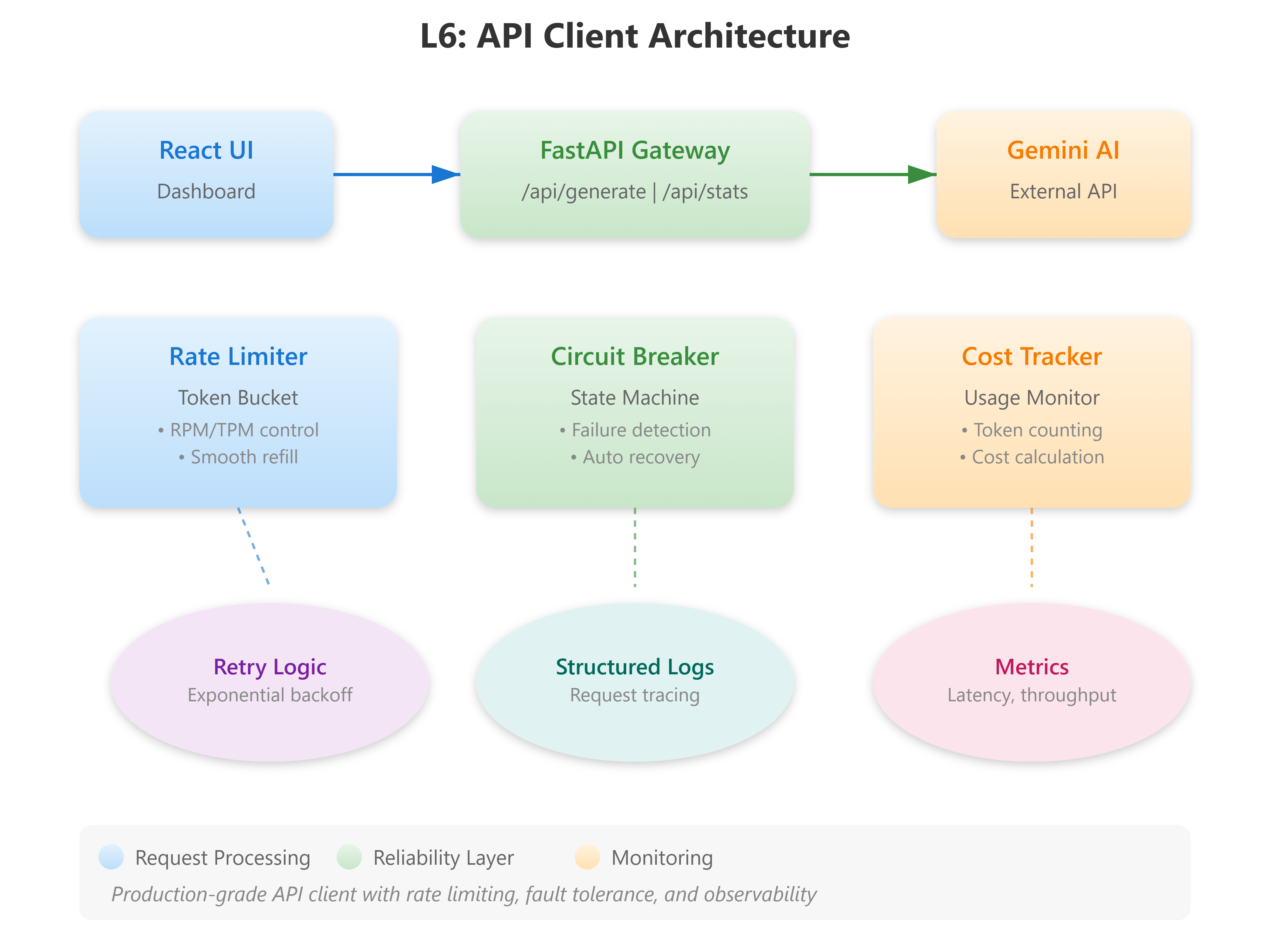
Component Architecture
Our system has four core components:
GeminiAPIClient: Async HTTP client with connection pooling
RateLimiter: Token bucket algorithm tracking RPM/TPM
CircuitBreaker: State machine for fault tolerance
CostTracker: Real-time usage and cost monitoring