
Highlights
What we build:
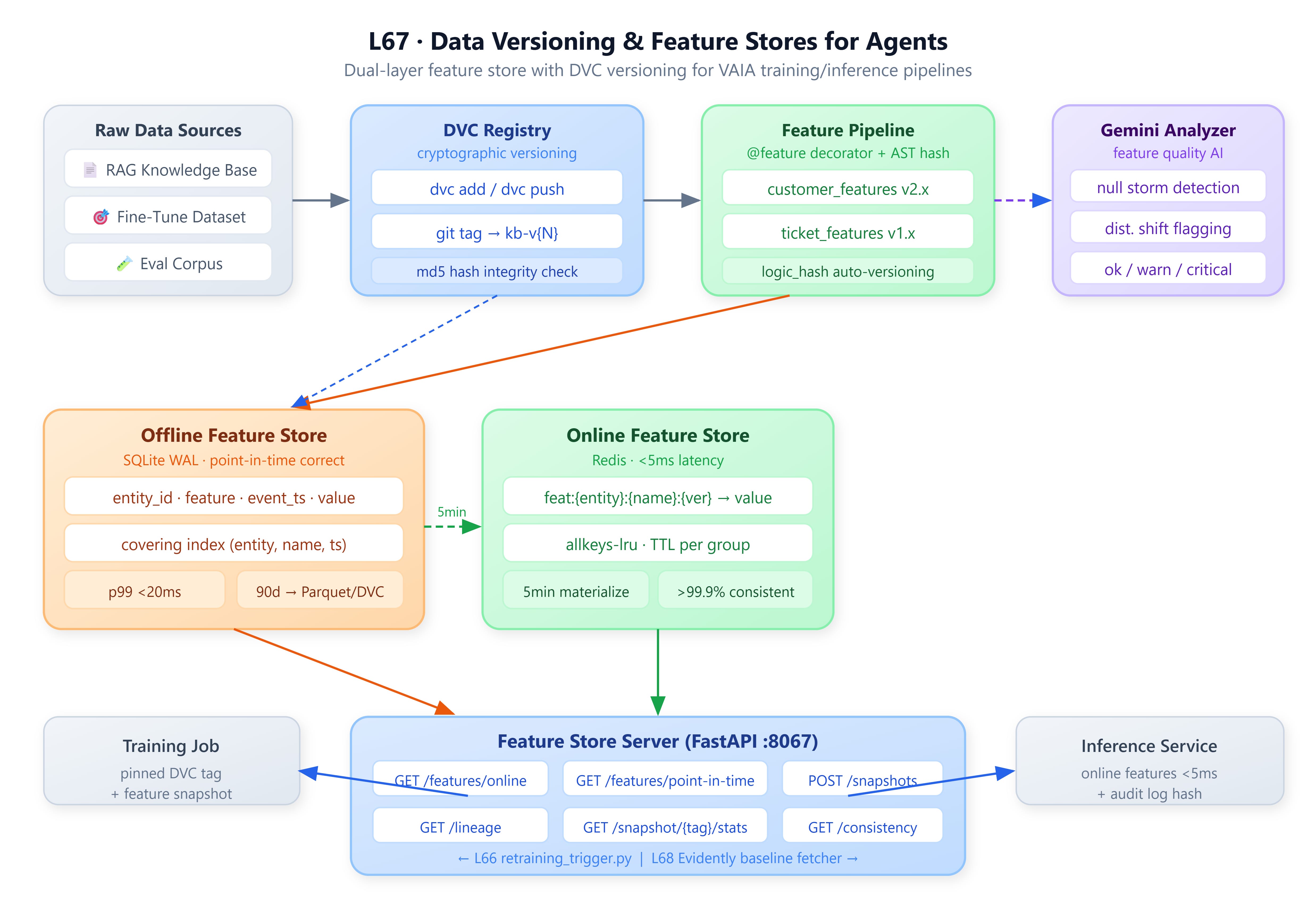
A production DVC registry that versions RAG knowledge bases, fine-tuning datasets, and agent evaluation corpora — with cryptographic integrity guarantees
A dual-layer feature store (offline SQLite WAL + online Redis) that eliminates training-serving skew for VAIA inference pipelines
Point-in-time correct feature retrieval so agent replays match the exact data state at any past timestamp
A Gemini-powered feature quality analyzer that flags schema drift, null storms, and distribution anomalies before they corrupt training runs
A React dashboard exposing data version timelines, feature lineage graphs, and store health metrics in real time
Connection to L66 (CT & Adaptive Agents): L66’s retraining pipeline fires when drift is detected — but it had no contract governing which data version gets used for that retraining. A triggered retraining that pulls stale or inconsistent feature data produces models worse than the one being replaced. This lesson gives L66’s retraining_trigger.py a versioned data contract: every training run gets a pinned DVC tag and a consistent feature snapshot from the offline store.
Enables L68 (CM & Drift Detection): L68 will monitor live agent outputs against baseline distributions. Those baselines must be computed from a known, reproducible dataset state — which this lesson’s feature store provides. L68’s Evidently integration will call our feature_snapshot_api to fetch reference feature distributions by DVC tag, making monitoring reproducible.
Architecture Context
Place in the 90-Lesson VAIA Path
We are 67 lessons deep. By now, your VAIA can self-train (L66), serves RAG pipelines (L40–L48), and runs multi-agent orchestrations (L55–L57). But there is a quiet liability accumulating: the data your agent was trained on is ephemeral. If you retrain today and again in three months, do you know precisely which documents were in your knowledge base each time? Which features were computed at what version of your entity resolution logic? Without answers, debugging regressions becomes archaeology.
Data versioning and feature stores are how production ML teams solve this. For VAIAs specifically, the problem is sharper — agent knowledge bases change frequently (new documents, updated embeddings), and the inference-time feature pipeline must match what the model saw during fine-tuning.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
