
Highlights
What we build:
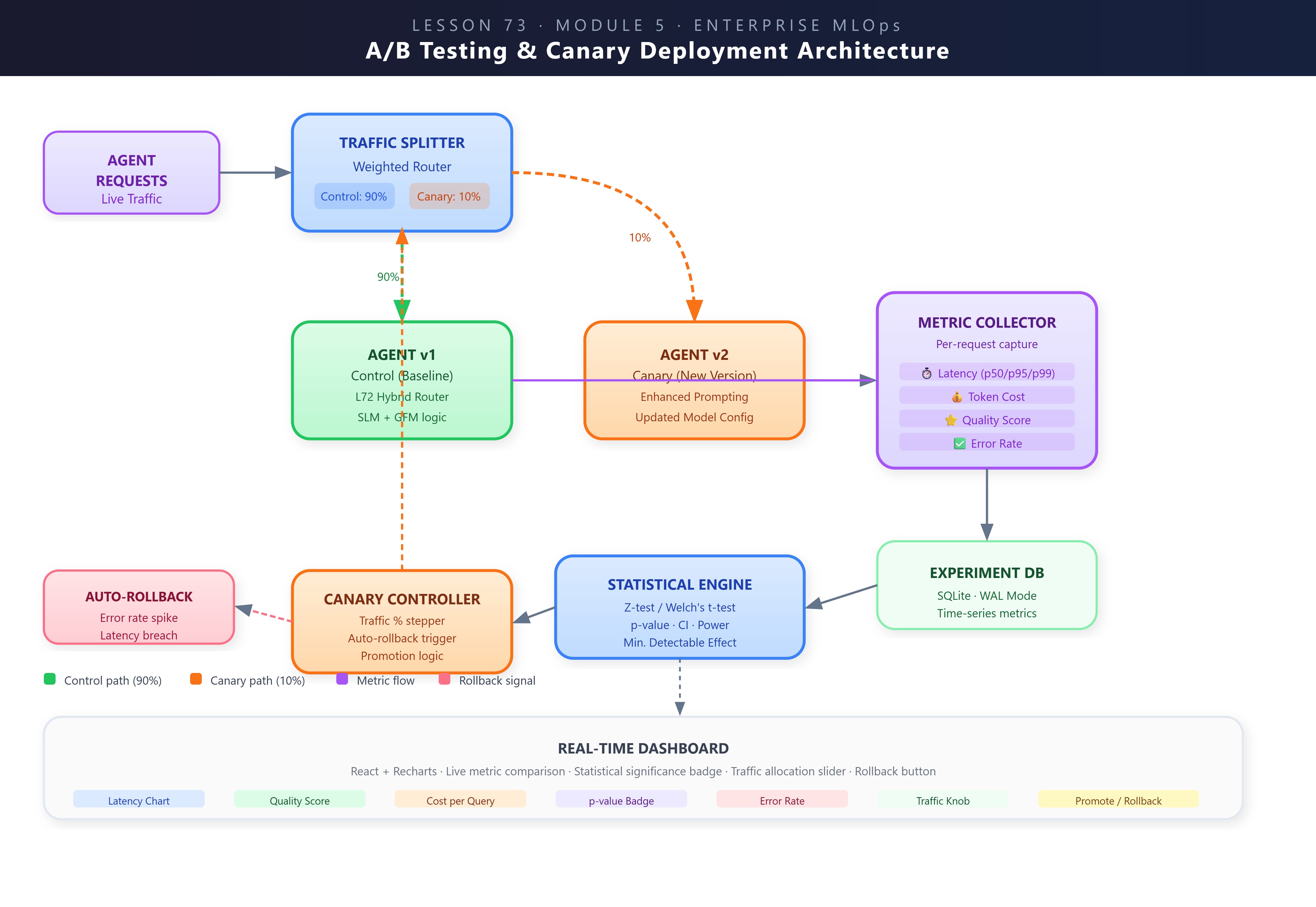
A weighted traffic splitter that assigns requests to agent versions using sticky user-hash routing, ensuring consistent user experience within an experiment
A per-request metric collector capturing latency (p50/p95/p99), Gemini token cost (bridged from L72’s
CostEstimator), quality scores (LLM-as-judge via Gemini), and error ratesA statistical significance engine running Welch’s t-test with configurable α, minimum detectable effect (MDE), and sample-size guards
A canary controller implementing the IDLE → CONFIGURING → RUNNING ↔ RAMPING → PROMOTED/ROLLED_BACK state machine with auto-rollback on threshold breach
A React real-time dashboard with live metric comparison charts, significance badges, a traffic-allocation slider, and one-click promote/rollback buttons
Connection to L72: L72 built a
HybridRouterthat dispatches queries to a local SLM or cloud Gemini GFM based on complexity. In L73, Agent v1 is that router — it’s the control baseline. Agent v2 is an enhanced variant with chain-of-thought prompting. TheCostEstimatorfrom L72 feeds directly into our per-variant cost tracking.
Enables L74: This lesson produces a fully Dockerized service with a clean REST API (
/experiment,/traffic,/metrics,/promote,/rollback). L74’s cloud deployment (Vertex AI / Azure ML) will consume these endpoints verbatim and add automated monitoring alerts on top.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
