
Highlights
What we build:
A ThoughtTraceCapture middleware that intercepts and persists every CoT step emitted by the Synthesizer and Validator agents
A ValidatorDecisionLog that records the structured reasoning path — evidence scored, thresholds crossed, rejection rationale — for every RAG validation cycle
An ExplainabilityEngine that reconstructs human-readable “explanation narratives” from raw trace data on demand
A TraceReplayEngine that lets compliance officers re-run any historical decision with the exact context snapshot frozen at decision time
A XAI Dashboard (React + Recharts) surfacing decision trees, confidence timelines, and per-claim attribution graphs
Connection to L79 — Governance & Compliance by Design: L79 gave us
ComplianceAuditLogger,DataAnonymizer, andAccessController. L80 extendsComplianceAuditLoggerwith structured reasoning payloads — not just what the agent decided, but why, step by step. The anonymization pipeline from L79 is applied to trace data before persistence, ensuring PII doesn’t leak into explanation artifacts.
Enables L81 — Bias Mitigation & Ethical AI: Every trace record L80 produces is the unit of analysis for L81’s fairness metrics. The ExplainabilityEngine exports a BiasAnalysisBundle — decision distribution by demographic cohort, claim attribution breakdown — consumed directly by aif360 pipelines in L81.
Architecture Context
Place in the 90-lesson VAIA path: Lessons 77–84 form Module 8: Responsible AI & Governance. L80 sits at the center — after compliance foundations (L79) and before fairness enforcement (L81). It is the observability spine for the entire module: every upstream governance artifact and every downstream fairness analysis depends on the trace records built here.
Integration with L79 components:
ComplianceAuditLogger.log_event()→ extended withreasoning_tracefield (structured JSON)AccessController.check_permission()→ gates who can read full traces vs. summary narrativesDataAnonymizer.anonymize()→ applied to agent inputs stored in trace snapshots
Module objectives alignment: XAI is the technical substrate for “Right to Explanation” under GDPR Article 22 and emerging AI Act Article 13. Without structured trace capture at the agent level, explanation requests cannot be fulfilled deterministically — you can only approximate. L80 makes explanation deterministic and auditable.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
Core Concepts
1. The Explanation Gap in Agentic RAG
Standard RAG logs record: query → retrieved chunks → final answer. What they omit is the Validator’s deliberation: which chunks passed semantic fidelity checks, what confidence threshold was used, why a synthesis step was flagged and re-routed. This is exactly the reasoning a regulator or end-user needs when exercising their Right to Explanation.
The Explanation Gap = (Decision made) − (Reasoning surfaced)
Closing it requires capturing CoT at the agent boundary, not the LLM boundary. The LLM emits tokens; the agent orchestrates decisions. These are different granularities, and conflating them produces traces that look detailed but explain nothing operationally useful.
2. Structured Thought Traces vs. Raw LLM Outputs
Raw LLM CoT streaming is unstructured text — it cannot be reliably parsed for compliance. VAIA XAI requires a typed trace schema:
ThoughtTrace {
trace_id: UUID
agent_id: str
step_type: Enum[RETRIEVAL, VALIDATION, SYNTHESIS, REJECTION, ESCALATION]
timestamp_ns: int
input_snapshot: dict # anonymized context at this step
reasoning_text: str # LLM-emitted thought
decision: dict # structured output of this step
confidence: float
evidence_refs: List[ChunkRef] # which corpus chunks influenced this step
parent_trace_id: UUID | None # supports trace tree reconstruction
}
This schema transforms free-form CoT into a queryable audit artifact. Compliance officers query by step_type=REJECTION to review every agent refusal. Fairness auditors join on agent_id and input_snapshot.demographic_cohort.
3. Validator Decision Provenance
The Agentic RAG Validator (introduced in L36–L45) is the highest-value tracing target. Each validation cycle produces:
Evidence scoring matrix: per-chunk relevance × faithfulness scores
Threshold evaluation: was the aggregated score above
min_faithfulness_threshold?Rejection rationale: if below threshold, which specific chunks failed and why
Re-routing decision: escalate to human, retry with expanded context, or synthesize with caveats
Capturing this as a structured ValidatorDecisionRecord provides complete provenance for any agent output.
4. Right to Explanation — Deterministic vs. Approximate
Two approaches exist:
Post-hoc explanation: run a separate explainability model on the output after the fact (LIME, SHAP on embeddings). Non-deterministic — the same output yields different explanations across runs.
Trace-based explanation (what L80 implements): replay frozen trace records. Deterministic — the explanation is always identical because it is the original reasoning, not a reconstruction of it.
GDPR Article 22 compliance requires deterministic explanation. Post-hoc methods are legally fragile.
5. TraceReplayEngine Design
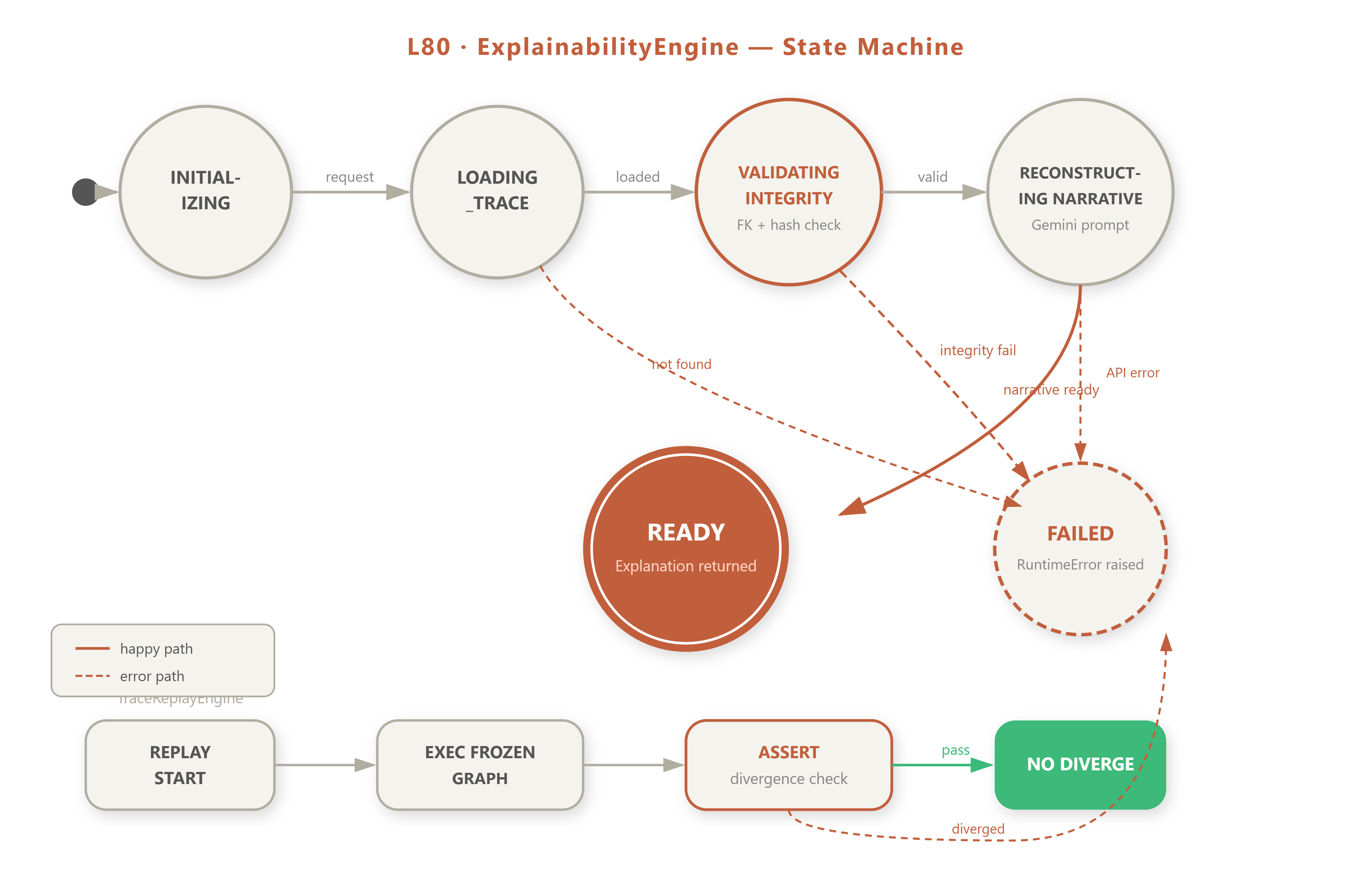
Replay is not re-inference. Re-inference sends the original query through the live agent again — model weights may have changed, RAG corpus may have been updated, results differ. Replay executes the frozen decision graph: same chunks, same scores, same threshold parameters, same Gemini prompt template, evaluated against the stored trace without calling any live API. It produces an identical outcome and a human-readable narrative. This is what makes it audit-proof.
VAIA Integration
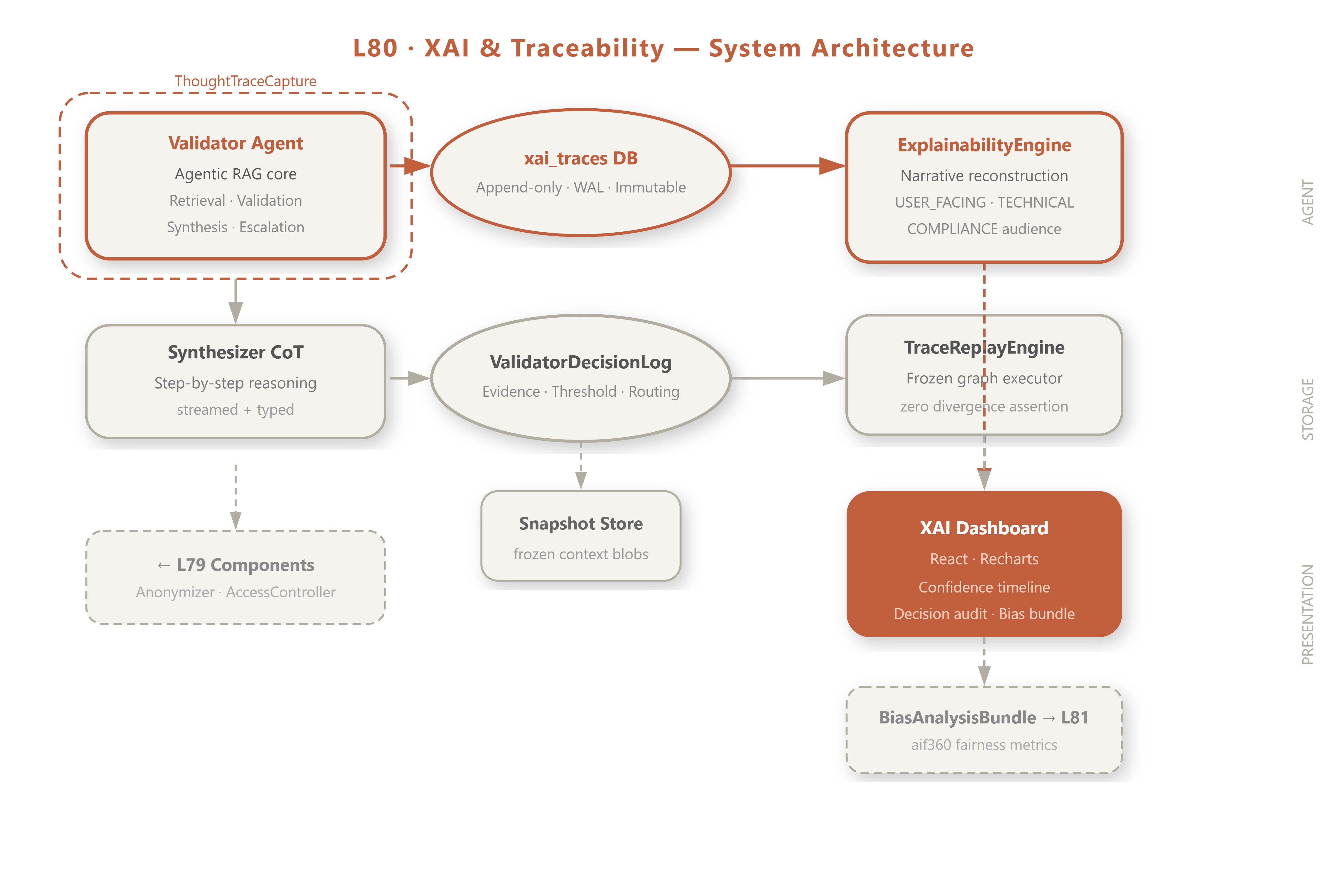
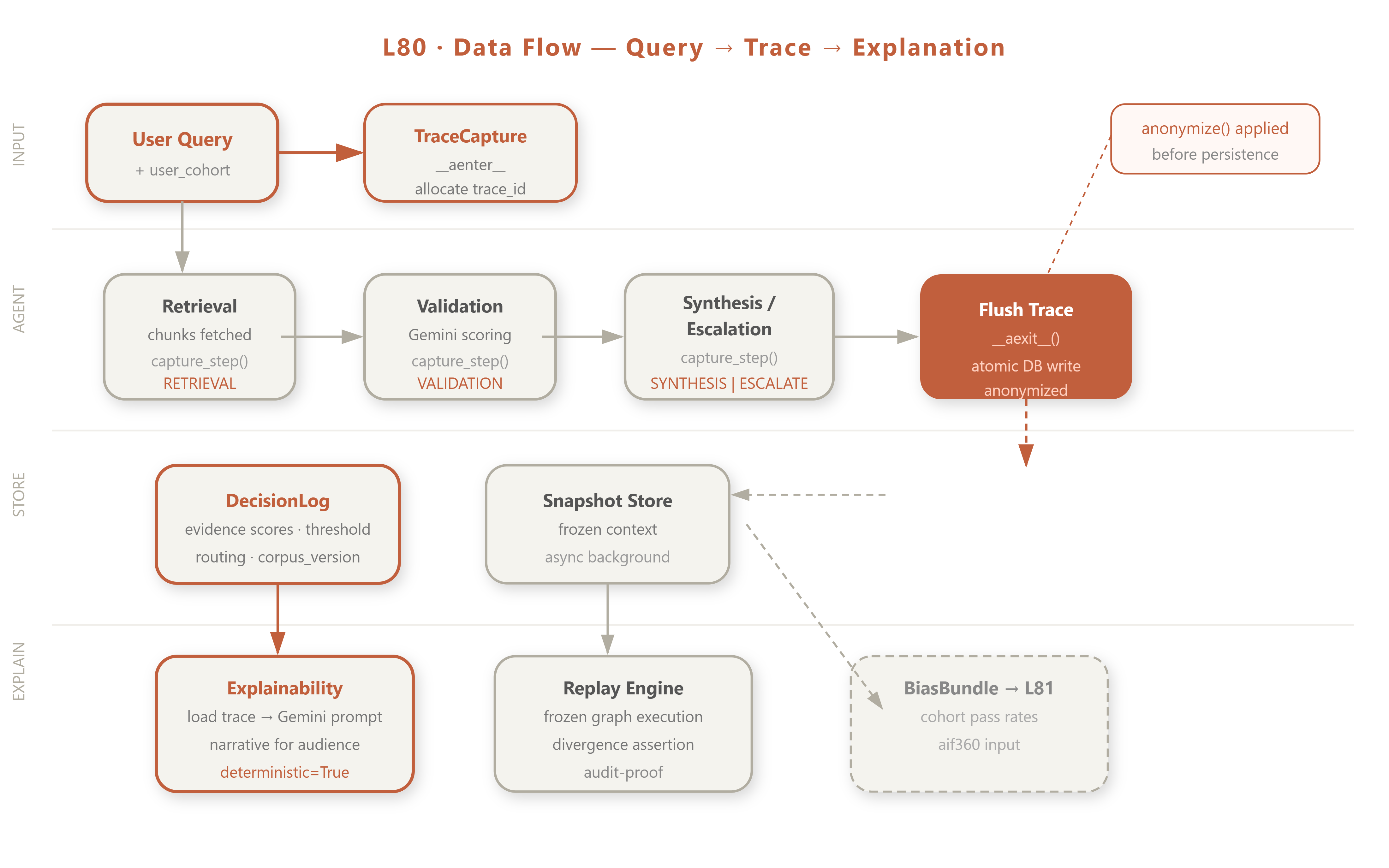
Production architecture fit: XAI tracing integrates at the middleware layer, not the application layer. ThoughtTraceCapture is an async context manager wrapping every agent invocation — zero changes to agent business logic. Traces are written to a dedicated xai_traces aiosqlite table with WAL mode, separate from the operational database, ensuring trace integrity even if the main app crashes mid-decision.
Enterprise deployment patterns:
Trace storage is append-only (no UPDATE/DELETE). Immutability is enforced at the DB layer via triggers.
Trace access is role-gated:
ROLE_COMPLIANCE_READfor full traces,ROLE_USER_READfor summary narratives only.Trace export to object storage (S3-compatible) is scheduled nightly — 7-year retention per financial regulatory mandates.
The
ExplainabilityEngineexposes a/explain/{decision_id}REST endpoint for integration with external GRC platforms.
Real-world examples:
Financial services: A loan decision agent must surface the top-3 evidence chunks and confidence scores that drove a rejection. L80’s
ValidatorDecisionLogprovides this directly.Healthcare: A clinical guidance agent must explain why it routed a query to human review. The
ESCALATIONstep type inThoughtTracecaptures this explicitly.Legal tech: A contract analysis agent must show which clause triggered a compliance flag.
evidence_refsin the trace maps to specific document chunk IDs.
Implementation
GitHub Link
https://github.com/sysdr/vertical-ai-agent-p/tree/main/lesson80/vaia-l80-xai
Component Architecture
The XAI stack has four layers:
Capture Layer —
ThoughtTraceCapture(async context manager) +ValidatorDecisionLog(Pydantic models + aiosqlite writer)Storage Layer —
xai_tracestable (append-only, WAL),trace_snapshotsobject store (frozen context blobs)Reconstruction Layer —
ExplainabilityEngine(trace → narrative),TraceReplayEngine(frozen graph executor)Presentation Layer — FastAPI
/explain/endpoints + React XAI Dashboard
Control/Data Flow
Query enters → ThoughtTraceCapture.__aenter__() allocates trace_id → agent processes steps → each step calls capture_step() which appends to in-memory trace buffer → on __aexit__(), full trace flushed to DB atomically → ValidatorDecisionLog.record() writes structured validator record linked to trace_id → async background task exports trace snapshot to object storage.
State Machine
The ExplainabilityEngine operates as a state machine over trace records, transitioning: INITIALIZING → LOADING_TRACE → VALIDATING_INTEGRITY → RECONSTRUCTING_NARRATIVE → READY (or FAILED on integrity check failure).
Coding Highlights
ThoughtTraceCapture — Async Context Manager
class ThoughtTraceCapture:
"""Zero-intrusion trace capture via async context manager."""
def __init__(self, agent_id: str, session_id: str, anonymizer: DataAnonymizer):
self.agent_id = agent_id
self.session_id = session_id
self.anonymizer = anonymizer
self.trace_id = str(uuid4())
self._steps: list[ThoughtTrace] = []
async def __aenter__(self):
self._start_ns = time.time_ns()
return self
async def capture_step(
self,
step_type: StepType,
reasoning_text: str,
decision: dict,
confidence: float,
evidence_refs: list[ChunkRef],
input_snapshot: dict,
) -> ThoughtTrace:
step = ThoughtTrace(
trace_id=str(uuid4()),
parent_trace_id=self.trace_id,
agent_id=self.agent_id,
step_type=step_type,
timestamp_ns=time.time_ns(),
input_snapshot=self.anonymizer.anonymize(input_snapshot),
reasoning_text=reasoning_text,
decision=decision,
confidence=confidence,
evidence_refs=evidence_refs,
)
self._steps.append(step)
return step
async def __aexit__(self, *_):
await TraceStore.flush(self.trace_id, self._steps)
Key insight: anonymizer.anonymize() runs on input_snapshot before persistence. PII never touches the trace DB.
ValidatorDecisionLog — Structured Provenance
class ValidatorDecisionLog(BaseModel):
decision_id: str = Field(default_factory=lambda: str(uuid4()))
trace_id: str
timestamp_utc: datetime
evidence_scores: list[EvidenceScore] # per-chunk relevance + faithfulness
threshold_used: float
aggregate_score: float
passed: bool
rejection_rationale: str | None # populated only on failure
routing_action: RoutingAction # SYNTHESIZE | ESCALATE | RETRY | REJECT
model_version: str # Gemini model tag at decision time
corpus_version: str # DVC commit hash of RAG corpus
class Config:
json_encoders = {datetime: lambda v: v.isoformat()}
corpus_version is the DVC commit hash from L75/L76 pipelines — complete lineage from training data through decision.
ExplainabilityEngine — Narrative Reconstruction
async def generate_explanation(self, decision_id: str, audience: Audience) -> Explanation:
record = await TraceStore.load_decision(decision_id)
steps = await TraceStore.load_trace_steps(record.trace_id)
# Build Gemini prompt with frozen trace data — no live retrieval
prompt = self._build_explanation_prompt(record, steps, audience)
response = await self.gemini_client.generate_content_async(prompt)
narrative = response.text
return Explanation(
decision_id=decision_id,
narrative=narrative,
supporting_steps=[s.model_dump() for s in steps],
generated_at=datetime.utcnow(),
is_deterministic=True, # always True — based on frozen trace
)
The audience parameter switches between TECHNICAL (includes raw scores and chunk IDs) and USER_FACING (plain-language narrative satisfying GDPR Article 22).
TraceReplayEngine — Frozen Graph Execution
async def replay(self, trace_id: str) -> ReplayResult:
steps = await TraceStore.load_trace_steps(trace_id)
frozen_context = await SnapshotStore.load(trace_id)
replayed = []
for step in steps:
# Execute step logic against frozen context — no live API calls
result = await self._execute_frozen_step(step, frozen_context)
replayed.append(result)
assert result.decision == step.decision, f"Replay divergence at step {step.trace_id}"
return ReplayResult(trace_id=trace_id, steps=replayed, diverged=False)
Divergence assertion makes replay failures explicit — critical for audit integrity.
Validation
Success criteria:
ThoughtTraceCaptureadds < 8ms overhead per agent invocation (P99)Every agent decision has a linked
ValidatorDecisionLogrecord (FK integrity enforced)ExplainabilityEngine.generate_explanation()returns within 3s for user-facing narrativesTraceReplayEngine.replay()produces zero divergence on 100 historical tracesTraces are immutable: DB trigger rejects any UPDATE/DELETE on
xai_tracestable
Benchmark targets:
Metric Target Trace capture overhead < 8ms P99 Explanation generation latency < 3s P95 Replay divergence rate 0% Trace storage compression ratio > 4:1 (gzip) Compliance query response time < 500ms
Verification methods:
pytest tests/test_xai.py::test_trace_immutability -v
pytest tests/test_xai.py::test_replay_zero_divergence -v
pytest tests/test_xai.py::test_explanation_latency -v
locust -f tests/load_test_xai.py --headless -u 50 -r 5 --run-time 60s
Assignment
Core task: Extend ValidatorDecisionLog to include a counterfactual_explanation field: “What would have changed if chunk X had scored 0.1 higher?” Use Gemini to generate this counterfactual from the frozen evidence score matrix.
Extension toward L81: Export a BiasAnalysisBundle from ExplainabilityEngine that groups decision outcomes by input_snapshot.user_cohort (demographic metadata, already anonymized). This is the exact input aif360 needs in L81 for disparate impact analysis.
Solution hints:
Counterfactual generation: increment each
evidence_score.faithfulnessby 0.1, recomputeaggregate_score, check ifpassedflips. If it does, that chunk is the counterfactual pivot.BiasAnalysisBundleschema:{cohort: str, decisions: [{passed: bool, confidence: float}]}grouped by cohort.Use
AccessController.check_permission("ROLE_COMPLIANCE_READ")before exposingBiasAnalysisBundle— it contains aggregated demographic data.
Looking Ahead
How L80 enables L81 — Bias Mitigation & Ethical AI: L81 needs a structured stream of agent decisions tagged with cohort metadata and outcome labels. L80’s ValidatorDecisionLog + BiasAnalysisBundle export is exactly this stream. Without L80’s trace infrastructure, L81 would need to instrument agents from scratch — instead, it inherits a complete, compliance-ready decision record. The aif360 fairness metrics in L81 operate directly on L80’s exported bundles.
Module progress: L80 completes the observability infrastructure for Module 8. Lessons 81–84 shift from capturing responsible AI artifacts to acting on them: bias mitigation, human-in-the-loop review, and model cards generation. Every one of those lessons reads from the trace DB built here.